SEO 対策(検索エンジン 最適化)
SEO は「Search Engine Optimization」の略で、 検索エンジン 最適化とも呼ばれます。
SEO 対策の基本は良質(適切)なコンテンツの提供とサイトの内容を適切に検索エンジンに理解させることです。また、現在では様々なデバイスに対応することも大切です。
以下は、Web ページを作成する際に考慮すると良い SEO 対策の基本的なことに関する説明などです。
タイトルの付け方や h1 タグの使い方などの SEO 内部対策や SEO 外部対策、構造化データ マークアップやサイトマップ、robots.txt の使い方などを解説しています。
更新日:2022年03月10日
作成日:2018年04月23日
SEO 対策を大きく分けると、「内部対策」と「外部対策」の2つに分類できます。
- SEO 内部対策
- 検索エンジンに高く評価されるために自分のウェブサイトの構造やコーディングなどを最適化する作業
- SEO 外部対策
- 外部のウェブサイトから自分のウェブサイトへリンクしてもらう(被リンクを集める)ための作業
また、日本の検索サイトのメインは Yahoo と Google ですが、Yahoo の検索エンジンは2011年から Google の検索技術を利用しているとのことなので、Google の SEO 対策ができていればほぼカバーできるようです(未検証)。但し、同じ検索技術を利用しているだけであって、検索結果が同じになるという訳ではありません。
Google が公開しているウェブマスター向けガイドライン(品質に関するガイドライン)が参考になります。また以下のような情報も公開されています。
SEO 内部対策
SEO 内部対策には、コンテンツのタイトルタグ、メタディスクリプション、見出しタグ、alt属性、リンクの設置、XMLサイトマップなど多くの要素があります。
title の付け方
ページのタイトルは、 head 要素内の title 要素(<title>~</title>)を使って記述します。
<title>レスポンシブ Web デザインの作り方(作成資料)/Web Design Leaves</title>
ブラウザのタブや検索結果では、以下のように表示されます。
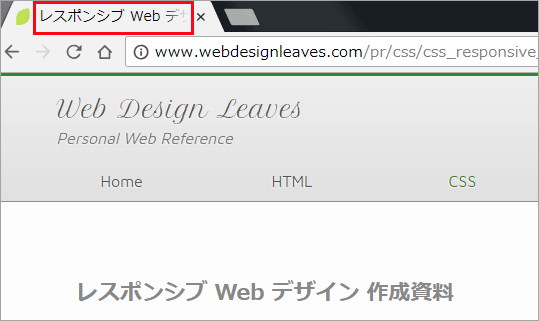

以下は「Search Console ヘルプ/Google」からの引用(抜粋)です。
わかりやすいページタイトルを作成する
タイトルは、検索結果のコンテンツをユーザーが一目でわかるように表示し、クエリとの関連性が高い理由をはっきりと伝えるうえで不可欠です。どのサイトをクリックするかはタイトルで決定することが多いため、ウェブページには質の高いタイトルを付けることが重要です。
- サイトのそれぞれのページに <title> タグでタイトルを付ける。
- 具体的でわかりやすいページタイトルを付ける。
- キーワードを詰め込んだようなタイトルは避ける。
- 同じタイトルや定型文を使用したタイトルは避ける。
- タイトルを目立たせる。ただし、簡潔になるように気を付けます。
- ページに対する検索エンジンのクロールの無効化に注意する。
title 要素の内容は、検索結果やブラウザのタブに表示されますが、ブラウザのタブに表示されるタイトルは目立ないのとタイトルが長い場合は一部しか表示されません(マウスオーバーすると表示されます)。
タイトル(title 要素)と大見出し(h1 要素)の関係は以下のように考えるとわかりやすいです。
- title 要素はタイトルを検索エンジンに伝えるために書きます
- h1 要素はタイトル(見出し)をユーザー(閲覧者)に伝えるために書きます
その結果として、title 要素と h1 要素の内容(テキスト)が同じになる場合もありますし、そうでない場合もあるかと思います。例えば、title 要素にはサイト名などが入ったりしますが、h1 には入らない等。
以前に比べると重要度は下がってきていますが、title 要素は現在でも SEO において最も重要な要素の1つです。以下がタイトルを付ける際に考慮する点です。
- キーワードを含めるようにする(可能であれば、キーワードを先に記述する)
- ページの説明を的確かつ簡潔に表現する
- 無用なスペースや句読点を使用しないようにする
- 可能であれば24文字程度以内に収める
- 他のページと同じタイトルにはしない(してはいけない)
ユーザーが検索した際に、表示された検索結果からタイトルで判断してクリックすることが多いと思われます。タイトルが検索したキーワードと同じであれば、目的のサイトと判断される可能性が高くなります。
そのため、上位表示させたいキーワードを先に記述するのが良いとされています。例えば会社名を入れる場合は、「キーワード | 会社名」などのようにします。
<title>jQuery Ajax(エイジャックス) / Web Design Leaves</title>
また、場合によっては重要なキーワードを2回使うと効果があるとされているようです。但し2回以上使用すると逆にペナルティを受ける可能性もあるので注意が必要です。
簡潔に表現する。「~を行います」などの冗長な表現や余計な文言は入れないようにします。「行います」で検索するのはおそらく少数ですので、不要と考えられます。
可能であれば24文字程度以内に収める。スマホでの検索結果の表示において、title タグが24文字以内であれば問題なくタイトル全体が表示されるようです。但し、無用なスペースや句読点が途中にあるとそれ以降が省略されてしまう可能性があるので注意が必要です。
ページの概要文(description)
以下は「検索エンジン最適化(SEO)スターター ガイド」からの引用です。
description メタタグは Google にページのスニペットとして使用される可能性があるため重要です。「可能性がある」と述べたのは、ユーザーのクエリに適合しやすい場合は、ページに表示されるテキストの関連部分が使用されることもあるからです。Google がスニペットに使用するのに適したテキストを検出できない場合に備えて、各ページに description メタタグを追加することをおすすめします。
description にはページの概要説明を記述します。meta 要素の name 属性に "description" を指定して、content 属性に記述します。
<meta name="description" content="ページの概要説明を記述" >
ユーザーが検索したキーワードが description に含まれている場合、検索結果にそのキーワードは太字で表示されます。そのため、description にもキーワードを入れるようにします。
また、ページの概要文は文章形式になっている必要はなく、箇条書きのようなものでも問題ありません。ページの内容でアピールしたい情報を記述するようにします。
以下がページの概要文を記述する際に考慮する点です。
- キーワードを入れ過ぎない(最大2個程度にする)
- 最大の文字数は100~120文字程度
- スマホでは50~60文字程度しか表示されないので、キーワードは最初から50文字以内に入れる
- 複数ページで同じ記述をしない
- コンテンツの内容をそのままコピペしない(要約したものを記述する)
PC の場合100文字前後が最適とされてきましたが、スマホでは検索結果に50~60文字程度しか表示されないので、伝えたいことを最初の50文字以内で表現するようにすると良いとされています。
Google Search Console の「検索での見え方」→「HTMLの改善」を見るとサイトのメタデータ(descriptions)に関する問題などを確認することができます。
「HTMLの改善」の機能は廃止されました。

h1 タグ
h1 タグは見出し要素(h1~h6)の中で一番重要度が高いタグ(大見出し)です。HTML5 では、h1 タグを同じページ内で複数使用することができます。
但し、複数の h1 タグを使用する場合は文書の構造(アウトライン)を section タグ等のセクションを明示する要素を使って明示的に検索エンジンに伝える必要があります。
h1 タグが h2 や h3 タグよりも SEO 的に効果が高いと言う理由で文書構造を無視して乱用すると、検索エンジンに誤って解釈される危険もあります。
以下は、複数の h1 タグと section 要素を使った例です。
<body>
<h1>Web 制作</h1>
<p>Web は...</p>
<section>
<h1>HTML</h1>
<p>...</p>
<section>
<h1>HTML4 / XHTML</h1>
<p>HTML は...</p>
</section>
<section>
<h1>HTML5</h1>
<p>HTML5 は...</p>
</section>
</section>
<section>
<h1>CSS</h1>
<p>...</p>
<section>
<h1>CSS3</h1>
<p>CSS3 は...</p>
</section>
<section>
<h1>SASS</h1>
<p>SASS は...</p>
</section>
</section>
</body>
上記の例のアウトラインは以下のようになります。(W3C の Validatorを利用した結果)
「Heading-level outline」は見出し要素による「暗黙的なアウトライン」を表していて、「Structural outline」が構造的なアウトラインを表しています。
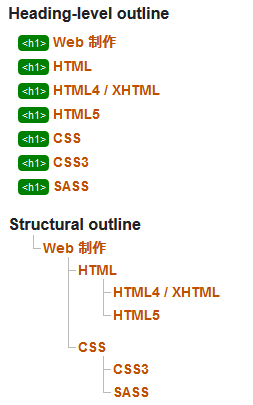
以下が h1 タグを記述する際に考慮する点です。
- h1 タグを複数使用する場合は、セクションを明示する要素を使って文書構造を明示する(または1ページに1つの h1 タグを使用する)
- キーワードを使用して簡潔に記述する
- 画像にしない(もし画像を使用する場合は、alt 属性の文字列を適切に編集する)
- p 要素とセットで使用する
- コンテンツの最初に配置する
見出しだけがあって次に続く文章がないのは不自然なので、p 要素とセットで使うのが良いとされています(他の見出し要素についても同じ)。可能であれば、p 要素はそれぞれの見出しに対する説明や関係する内容を記述します。
サイト名(社名やロゴなど)とページタイトル
サイト名やページタイトルをどのタグを使って記述するかは、いろいろな方法があると思いますが、以下が良く使われる方法のようです。
- トップページの場合:サイト名(社名やロゴなど)を h1 要素でマークアップ
- 下層ページの場合:ページタイトルを h1 要素でマークアップ(サイト名は p 要素等でマークアップ)
但し、下層ページでもトップページ同様にサイト名を h1 要素でマークアップしても問題はないと思われますし、ヘッダーを共通パーツにした場合、管理が楽になります。
画像に h1 要素を設定する場合
可能であればテキストを使用するのが良いのですが、サイトのロゴなどを h1 要素でマークアップする場合は、img 要素の alt 属性の文字列を適切に指定する必要があります。
cssで「text-indent: -9999px;」でテキストを記述する方法もありますが、alt 属性の方がシンプルで、検索エンジンやスクリーンリーダーを使うユーザーも理解することができる alt 属性にテキストを記述した方が良いようです。
その他の見出し要素
見出し要素には h1~h6 の6種類があり、h1 が一番重要度が高く h6 が一番低くなっています。文書構造に合わせて適切なタグを使用するようにします。
以下が h2~h6 タグを使用する際に考慮する点です。
- キーワードを使用して簡潔に記述する
- 文書構造に合わせて出現順を考慮する
- title や h1 と同じにしない
- 画像にしない
- p 要素とセットで使用する
テキスト関連
文字の大きさ
デザインのために文字を小さくしてしまう場合がありますが、あまり小さすぎると読みにくいため本文は16px程度にすると良いとされています。
背景色と文字色
背景色と文字色が近いと読みにくくなり、SEO 的にも悪い影響を受ける可能性があるので、文字色が背景色と近くないようにします。
適度な段落
適度に段落分けすることで、ユーザーに見易くなるのと同時に検索エンジンにも理解されやすくなる可能性があります。
無駄な改行をしない
見栄えのための改行タグ(br 要素)による改行はなるべくしない。
文字間にスペースを入れない
デザイン的な理由で文字間にスペースを入れてしまうと、検索エンジンに正しく理解されない可能性があります。そのため、見栄えのための文字間のスペースは、CSS(letter-spacing)で調整します。
画像 img タグ
画像を最適化するには、画像にわかりやすいファイル名を付けて、alt 属性の説明を入力します。alt 属性は視覚障害者の方のための読み上げ機能の他に、Google が画像の内容を把握するのにも使われています。
簡潔でわかりやすいファイル名
画像のファイル名は、画像を連想しやすいファイル名にすると良いとされています。可能であればファイル名を見ただけで、どのような画像なのかがわかるようなファイル名にします。
但し、長いファイル名や複雑なファイル名は避けるようにします(短くてわかりやすいものが適しています)。
例えば犬の画像であれば dog.jpg や big-dog.jpg(大きな犬の場合)などになります(拡張子が jpg の場合)。ハイフン「-」を使うとその前後で2ワードと認識されるのでアンダーバー「_」よりも有効とされています。但し、複数のハイフンの使用はなるべく避けたほうが良いようです。
画像サイズの指定
レスポンシブ等で PC 用とスマホ用を使い回す機会も多く画像の縦横サイズを指定していない場合も多いと思いますが、width と height を指定しておくことで、ページの表示が少し早くなり、ユーザビリティにも影響して直帰率などの改善が期待できます。
可能であれば、サイズ(width と height)を指定するのが良いとされています。
<img src=containing-block.jpg" width="569" height="310" alt="親要素と子要素のボックスモデルの関係を表した図">
alt 属性
画像が表示できない環境では、alt 属性の値が代替的に表示・表現され、音声ブラウザで読み上げられたり、検索クローラがどのような画像が埋め込まれているかを判断します。
alt 属性には、その画像が表すものを言葉で説明した文章を入れます(画像を単に説明するものではなく、画像を代替するテキストであることを意識して記述する必要があります)。もし画像が表示されず、alt 属性の値が表示された場合でもページの内容の意味が変わらないようにします。
<img src="blue-bird.jpg" alt="森の中を飛ぶ青い鳥の写真(カラー)">
但し、画像が装飾または補足的なものである場合は、alt 属性の値は空("")にします。
<img src="spacer.gif" alt="">
また、画像をリンクやボタンとして使用する場合は alt 属性を設定してリンクやボタンの目的を伝えるテキストを記述します。これによりリンク先のページについて検索エンジンが理解しやすくなります( alt 属性の値はテキストリンクのアンカー テキストと同様に扱われます)。
<p><a href="index.html"><img src="home.jpg" alt="ホームに戻る"></a></p>
キャプションの利用
figcaption 要素を使ってキャプション(画像の説明)を付けるのも SEO 的に効果があるとされています。
<figure> <figcaption>ウェストビレッジの古い建物</figcaption> <img src="/images/wvillage.jpg" alt="古い建物の多いビレッジの風景" /> </figure>
キーワードを入れ過ぎない
alt 属性のテキストは文字数に制限がありませんが、だからと言って画像と関係のないキーワードを入れたり、関連キーワードを詰め込のは良くありません。逆にペナルティとなる可能性があります。
URL や ドメイン名
サイトの URL 構造はできる限りシンプルにします。わかり易い URL は見ただけで内容を推測することができるので、コンテンツ情報を伝えるのに効果があります。
Web ページの URL に上位表示したい検索キーワードを含めた方が、含めないよりも Google で上位表示している傾向があるようです。但し、URLに重要なキーワードを詰め込んでもキーワード順位向上の助けにはならないとされているようです。
ドメイン名にキーワードが含まれている方が上位表示されやすいと言われますが、その影響はあまり大きくないようです。※既存のドメインをわざわざ変更する必要はないと考えられます。
Google の Search Console ヘルプ「シンプルな URL 構造を維持する」には、シンプルでわかり易い URL が良いとされています。
ファイル名やディレクトリ名
ファイル名やディレクトリ名も見る側がわかり易い名前を付けることで、検索エンジンのクロールを促す効果が期待できます。
また、区切り文字にはハイフン(-)を使うことが推奨されています。
URL では区切り記号を使うと効果的です。http://www.example.com/green-dress.html という URL の方が、http://www.example.com/greendress.html という URL よりずっとわかりやすくなります。URL にはアンダースコア(_)ではなくハイフン(-)を使用することをおすすめします。
ディレクトリ名、ファイル名のいずれか1つにそのページのキーワードを1回含めたほうが SEO 的に効果があるようです。但し、1つの URL の中に複数回同じキーワードを繰り返し記述するのはスパム判定されるリスクがあります。
キーワード出現率
「キーワード出現率」とは、ある Web ページ内において、どのキーワードがどのぐらいの割合で使用されているかを表すものです。
以前は、表示されるページにそのキーワードが多く含まれていれば、検索結果で上位表示されると考えられていたこともありますが、現在ではキーワード出現率は SEO の上位表示効果はないと考えられていて、キーワード出現率が何パーセント以上だから、検索結果で上位表示されるというような目安のようなものはないとされています。
キーワード出現率のことを考えて、不自然なコンテンツを書くより、ユーザーに伝わりやすい、理解しやすいようなコンテンツを書くことが大切ということになります。本来ユーザーのためとなるコンテンツがわかりにくくなったり、読みにくいページになっては本末転倒です。
また、過剰にキーワードが含まれている場合はスパム扱いされてしまう可能性があります。
「キーワードの乱用」Google Search Console ヘルプ
キーワード出現率は、以下のような無料ツールを使って調べることができます。
共起語
共起語とは、キーワードとよく一緒に使われることの多い単語や関連性があり同じ文脈で使われやすい単語のことです。
例えば、「CMS」に関する共起語は以下のようなものがあります。
- サイト
- Web
- コンテンツ
- 構築
- 導入
共起語を盛り込むと、SEO効果があると言われていますが、定かではありません。
コンテンツ(文章)を考える際の参考にはなると思います。但し、共起語を意識しすぎて、わかりにくくなったりするのは逆効果です。
共起語検索には以下のような無料ツールがあります。
関連キーワード
関連キーワードとは、検索キーワードと関連性の高いキーワードのことです。
関連キーワードは、Google のオートコンプリート(サジェスト機能)や検索結果の下に表示される関連する検索キーワード、専用ツールで確認することが可能です。
共起語と同様、単に関連キーワードを盛り込めば SEO 効果が得られるものではありませんが、Web サイトのコンテンツ(文章)や構成を考える上で参考にすることができます。
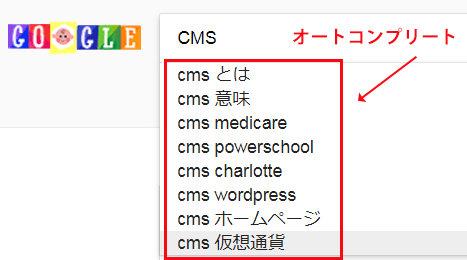

関連キーワードを取得ツールには、以下のようなものがあります。
- 関連キーワード取得ツール(仮名・β版)
- goodkeyword
- Google トレンド
- Keyword Tool
- Google キーワードプランナー(AdWords にログイン後、ツールからキーワードプランナーを選択)
内部リンク
内部リンクとは、同じ Web サイト内でページ同士を繋ぐリンクです。具体的には、グローバルメニュー、パンくずリスト、サイドナビやフッターリンク、記事(コンテンツ)中のリンク等です。
内部リンクを調整(整備)することにより SEO の効果を得られることがあります。
わかり易い(使いやすい)リンク
ユーザーが目的のページに簡単にたどり着けるかや、現在のページの位置をすぐに把握できるかがとても重要です。その意味でもパンくずリストは有効な手段です。
また、そのページと同類・同列や近い内容のページへのリンクを設けることもユーザーの利便性を高めます。
リンクの階層があまり深くならないように配慮することも大切です。最大でトップから3、4クリックで到達できるのが望ましいとされています。
わかり易いリンク名
リンクに使われるテキストのことをアンカーテキストと言います。このアンカーテキストにキーワードを入れると、検索エンジンに対してリンク先のページの内容を伝えることができるため SEO 効果が望める可能性があります。
以下のようなテキストリンク(アンカーテキスト)が SEO に有効とされているようです。
- キーワードを使ったリンク
- 同義語を使ったリンク
- 共起語を使ったリンク
インデックスファイルへのリンク
一般的には下記の2つのアドレスにアクセスすると、同じ内容のページが表示されます。
- http://www.example.com/
- http://www.example.com/index.html
ナビゲーションやページ内からのインデックスファイルへのリンクを index.html などファイル名を付けるか、ファイル名なしの「/」にするか、どちらかに統一する方が、アクセスが分散されないで済みます。
また、最後の「/」を付けるか付けないかも統一した方が、同様にアクセスが分散されないで済みます。
関連:URL の正規化
重要なページに内部リンクを集める
重要なページにリンクを集めるということも SEO 的に効果があるようです。具体的には、記事内に重要なページへの内部リンクを増やします。
但し、単にリンクを増やせば良いというわけではありません。ユーザビリティやコンテンツの内容を考えて、関連性のあるキーワードで内部リンクを設置するようにします。
実際にどのようなアンカーテキストが使用されているかを調べることができる、以下のようなサイトもあります。
URL の正規化
以下は全て同じページを表示しますが、それぞれ異なるページとして検索エンジンに判断される可能性があり、従ってアクセスが分散されてしまう可能性があります。
- www の有無
- http://www.example.com/
- http://example.com/
- インデックスページの有無
- http://example.com/
- http://example.com/index.html
- http または https
- http://example.com/
- https://example.com/
- 末尾のスラッシュ「/」の有無
- http://example.com/foo
- http://example.com/foo/
URL の正規化とは、同じページが異なる URL で存在しないように URL を統一することです。
例えば、http://example.com/index.html にアクセスがあった場合は、http://example.com/ に「301リダイレクト」を使ってリダイレクトするなどの方法があります。
.htaccess で301リダイレクトを使って URL を統一(正規化)する方法は以下を参照ください。
これらの正規化が全て必要かどうかは別にしても、自分でリンク等に記述する URL はどちらかに統一して記述する必要があります(した方が良いと思います)。
末尾のスラッシュ「/」の有無は、ドメイン名(ホスト名)の直後のスラッシュ「http://example.com/」は、あっても無くても同じページと見なされるようですが、それ以外は異なるページと判定される可能性があるようです。以下は Google+ からの引用です。
The "trailing-slash or not" question comes up from time to time, so I thought I'd write something short up. tl;dr: the slash after a hostname or domain name is irrelevant, you can use it or not when referring to the URL, it ends up being the same thing. However, a slash anywhere else is a significant part of the URL and will change the URL if it's there or not. This is not SEO-specific, but just how websites work :).
以下の URL の指し示す場所は異なります。
- http://hostname/path
- http://hostname/path/
ドメイン名(ホスト名)の直後のスラッシュ以外の末尾のスラッシュ「/」の有無はサーバーの設定によっても異なるので(例えば、スラッシュなしの場合、自動的にスラッシュが補完されるなど)、使用しているサーバーの環境を確認する必要があります。
参考ページ:
重複した URL を統合する(Search Console ヘルプ)
「/」と「/index.html」が別々にトラッキングされる(Google アナリティクスヘルプ)
重複コンテンツ
重複コンテンツとは、URL が異なっているのに、タイトルや description、コンテンツ(文章)が他のページと完全に同じかほぼ同じ場合のコンテンツのことです。
重複コンテンツだからと言う理由で Google からペナルティを受けることはほぼないようですが、以下のような問題が起きる可能性があります。
- 重複コンテンツがあると、どれか一つしか検索結果に表示されない(Google の仕様。表示されるページは Google により決定)
- 複数 URL にアクセスが分散する(本来ならば一つの URL に集まるはずの被リンクが複数に分散してしまう)
参考ページ:
重複するコンテンツ(Search Console ヘルプ)
重複した URL を統合する(Search Console ヘルプ)
重複コンテンツに対処するには、いかのような方法があります。
301 リダイレクトを使用する
ユーザーがアクセスする URL が1つで構わない場合(他のページを廃止する場合)は、.htaccess ファイルで 301 リダイレクト(RedirectPermanent)を使用します。
301リダイレクトとは、サイトやページを恒久的に移転先へ転送することで、ユーザーや検索エンジンが正しいページにたどり着くことができるようにする方法です。
この方法は、重複したページを廃止するときにのみ使用します。
rel="canonical" リンクタグを使用する
ページのヘッダーに rel="canonical" を指定したリンクタグを使用すると、そのページが別のページの重複であることを示すことができます。
rel="canonical" リンクタグは、正式な URL を検索エンジン側に伝えるためのタグです。
重複した全てのページで link 要素でマークアップし、<head> 要素内(なるべくソースの上部)に記述します。href 属性にはインデックス に登録させたい URL(正規ページ)を絶対パスで指定します。
<link rel="canonical" href="https://example.com/honmono.html">
例えば、色違いやサイズ違いの商品があり、それ以外は全く(またはほぼ)同じ内容でそれぞれに固有の URL を設定している場合、重複ページとして認識される可能性があります。そのような場合、rel="canonical" リンクタグを使用すると良いかもしれません。
以下の例は、3つの色違いのレンタカー(色以外の内容は全く同じかほぼ同じ)のページに固有の以下の3つ URL を設定している場合です。
- http://www.example.com/rental/green-car.html
- http://www.example.com/rental/blue-car.html
- http://www.example.com/rental/red-car.html
このような場合は、インデックス に登録させたい URL(正規ページ)を決めて、それ以外のページに rel="canonical" リンクタグを設定します。
例えば、green-car.html を正規ページとすると、blue-car.html と red-car.html のページに以下のような rel="canonical" リンクタグを設定します。
この指定を行うと、blue-car.html と red-car.html のページは Google などの検索対象外になります(検索結果に表示されないようになります)。
<link rel="canonical" href="https://example.com/rental/green-car.html">
参考ページ:rel=canonical 属性に関する 5 つのよくある間違い
但し、上記の方法の対象は HTML ページのみとなり、PDF などのファイルには利用できません。このような場合、次の rel=canonical HTTP ヘッダーを利用できます。
rel=canonical HTTP ヘッダーを利用
サーバーを設定する権限がある場合は、rel="canonical" の(HTML タグではなく)HTTP ヘッダーを使用すると、HTML 以外のドキュメント(PDF ファイルなど)について正規 URL を指定できます。
例えば、複数の URL で 1 つの PDF ファイルを表示する場合、重複した URL について次のような rel="canonical" HTTP ヘッダーを返して、その PDF ファイルの正規 URL がどれであるかを Google に伝えることが可能です。
Link: <http://www.example.com/downloads/white-paper.pdf>; rel="canonical"
上記のヘッダーを .htaccess で出力するには Header ディレクティブの引数に set を指定して応答(Link)ヘッダを設定します。
Header set Link "<http://www.example.com/downloads/white-paper.pdf>; rel=\"canonical\""
但し、上記の記述だと配下の全てのファイルのヘッダーにセットされてしまうので、「sample.pdf」のみに適用するには、以下のように Files ディレクティブ を使用します。
<Files "sample.pdf"> Header set Link "<http://www.example.com/downloads/white-paper.pdf>; rel=\"canonical\"" </Files>
参考ページ:
HTTP ヘッダーでの rel="canonical" 属性に対応しました(ウェブマスター向け公式ブログ )
.htaccessを使ってHTTPヘッダーにrel="canonical"を指定する方法
関連ページ:HTTP ヘッダ(PHP)
PC用とスマホ用で別のページを用意している場合
- PC用のページの head 内に link rel="alternate" を記述してスマホ用ページを指定します。
- またスマホ用のページの head 内に link rel="canonical" を記述して PC 用ページを指定します。
例えば、パソコン用 URL が http://example.com/sample.html で、対応するスマホ用 URL が http://m.example.com/sample.html である場合、以下のような記述になります。
パソコン用ページ(http://example.com/sample.html)には、次の記述を追加します。
<link rel="alternate" media="only screen and (max-width: 640px)" href="http://m.example.com/sample.html">
- rel="alternate" 属性は、このタグがパソコン用ページの代替 URL を指定していることを示します。
- media 属性の値は、代替 URL を使用するメディア機能を指定する CSS メディアクエリ文字列です。上記の場合、モバイル端末がターゲットの場合に一般に使用されるメディアクエリ(640px以下)を指定しています。
- href 属性は代替 URL の場所、つまり m.example.com のページ上の場所を指定します。
スマホ用ページ(http://m.example.com/sample.html)には、次の記述を追加します。
<link rel="canonical" href="http://example.com/sample.html">
- rel="canonical" は、正式な URL を検索エンジン側に伝えるためのタグです。
※rel="alternate" と rel="canonical" のマークアップを使用する場合、モバイル用ページとそれに対応するパソコン用ページの関係が必ず 1 対 1 になるようにする必要があります。同じモバイル用ページを複数のパソコン用ページから参照するような記述は避けます(その逆も同様です)。
参考ページ:別々の URL (developers.google.com)
タイトルや description の重複は、Google Search Console の「検索での見え方」→「HTMLの改善」を見るとサイトのメタデータ(descriptions)に関する問題などを確認することができます。
「HTMLの改善」の機能は廃止されました。
正規化する場合の注意点
「重複した URL を統合する」の「一般的なガイドライン」には以下のようなことが記載されています。
- robots.txt ファイルを正規化の目的で使用しないでください。
- URL 削除ツールを正規化のために使用しないでください。URL 削除ツールは、すべてのバージョンの URL を検索結果から削除するものです。
- 同一または異なる正規化方法を使用して、複数の異なる URL を同じページの正規 URL として指定しないでください(たとえば、サイトマップで特定の URL を指定する一方で、同じページに対し、rel="canonical" を使って別の URL を指定する、といったことはしないでください)。
- 正規ページの選択を妨げる手段として noindex を使用しないでください。このディレクティブは、正規ページの選択を管理するものではなく、インデックスからページを除外するためのものです。
類似ページの判定
重複コンテンツや類似ページの判定を自動で行ってくれるツールには、以下のようなものがあります。
Above the fold
Above the fold(アバブ・ザ・フォールド)とは、スクロールしないで見る事ができる画面の範囲(ファーストビュー)のことです。
初めてユーザーがページを訪れた場合、Above the fold の情報を見て「このページには必要な情報がありそうだ」とか「良い情報がなさそうだ」などといった判断をする可能性が高いため、この領域にはページ内で最もユーザーに伝えたい重要なコンテンツや、下にスクロールを促すためのコンテンツやリンク、アイキャッチ画像などを配置して、直帰を回避するための工夫をこらしていく必要があります。
Google には、ページ内の構成がどのように配置されているかを診断するページレイアウトアルゴリズムがあり、ページ内の構成がどのように配置されているかを診断し、ユーザビリティの観点から評価します。
ページレイアウトアルゴリズムは、Above the fold を広告が多く占めているサイト(ユーザーエクスペリエンスを損ねているサイト)の評価を下げるアルゴリズムです。
Above the fold を広告スペースが多く占領している場合、ユーザーのみならず、検索エンジンから評価を落とす危険性があるので注意が必要です。
Above the fold に関しては以下のような点を考慮します。
- 重要なコンテンツを配置する
- 重要タグを使って記述する(h1, h2 要素及びそれらを補足する p 要素)
h1 を記述する
h1 を補足する文章(p 要素)を間に入れる
h2 を記述する
h2 を補足する文章(p 要素)を間に入れる - メインビジュアル(アイキャッチ画像)の採用を検討する
ページの表示速度を評価してくれるツール PageSpeed Insights で確認してみると良いかも知れません。
PageSpeed Insights にアクセスして、調べたいページの URL を入力して「分析」をクリックするとそのページを評価してくれます。
モバイル用及び PC 用の評価を確認することができます。「最適化についての提案」という項目に改善案が表示されます。
「表示可能コンテンツの優先順位を決定する」が改善案として提示されている場合、Above the fold の内容を確認・修正した方が良い可能性があります。以下は「スクロールせずに見える範囲のコンテンツのサイズを削減する」からの抜粋です。
スクロールせずに見える範囲の重要なコンテンツが最初に読み込まれるように HTML を構成する
ページの主要なコンテンツを最初に読み込みます。サーバーからの最初のレスポンスで重要なページ部分のレンダリングに必要なデータがすぐに送信され、残りは後で送信されるように、ページを構成します。
参考ページ:PageSpeed Insights について
パンくずリスト
パンくずリストとは、閲覧しているページ が、Web サイト全体のどの階層、カテゴリ、位置にあるのかを明示した以下のようなリンクです。
<ol class="breadcrumb"> <li><a href="../index.html">Home</a></li> <li><a href="index.html">HTML</a></li> <li>SEO 対策(検索エンジン 最適化)</li> </ol>
パンくずリストの設置には、以下のようなメリットがあります。
- ユーザーがどのページを読んでいるのかが一目でわかる
- 検索エンジンのクローラー巡回を手助けする役割
- パンくずリストは内部リンクとなり、対策キーワードをアンカーテキスト(リンク付きテキスト)にできるので、内部 SEO に有効
パンくずリストには可能であれば、ターゲットキーワードを含めるのが有効とされています。パンくずリストは構造上、上層にあるページに下層ページからのリンクが集中するようになっています。そのため、キーワードを意識した階層構造を作ると効果的です。
例えば文房具を販売するサイトの場合、「ホーム>筆記用具>万年筆」というように「筆記用具」や「万年筆」と言うキーワードを入れたりすることができます。ホームの部分をサイト名やキーワードにするのも1つの方法です。
また、そのページをパンくずリストに含めるかどうかは、そのサイトの性質や文字数によりケースバイケースになると思います。
※ SEO を意識し過ぎて、対策キーワードを無理に入れたりすることで、わかりづらかったり、見づらかったりするようなパンくずリストにならないように注意する必要があります。
関連ページ:
microdata で構造化マークアップ
検索エンジンに確実にパンくずリストであることを認識させる方法として、構造化(データ)マークアップがあります。
構造化マークアップを使ってパンくずリストを適切に設置すると、以下のように検索結果にパンくずリストによるサイトの階層構造が表示され、カテゴリーなどが一目でわかるようになります。
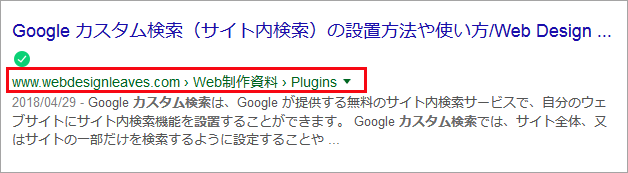
以下は schema.org のボキャブラリーを使った microdata での構造化マークアップの例です。
microdata は、ページに記述されている HTML 要素に情報を追加していきます。既存の HTML 要素に構造化データ用の属性を追加したり、追加の meta タグをコンテンツの子要素として追加したりします。
HTML の構造に変更を加えない方法としては、次項の「JSON-LD」があります。
<ol itemscope itemtype="http://schema.org/BreadcrumbList">
<li itemprop="itemListElement" itemscope itemtype="http://schema.org/ListItem">
<a itemprop="item" href="../index.html"><span itemprop="name">Home</span></a>
<meta itemprop="position" content="1">
</li>
<li itemprop="itemListElement" itemscope itemtype="http://schema.org/ListItem">
<a itemprop="item" href="index.html"><span itemprop="name">HTML</span></a>
<meta itemprop="position" content="2">
</li>
<li itemprop="itemListElement" itemscope itemtype="http://schema.org/ListItem">
<span itemprop="name">SEO 対策(検索エンジン 最適化)</span>
<meta itemprop="position" content="3">
</li>
</ol>
最初に検索エンジン(Google)に対して、「ここからここまでが、パンくずリストの microdata です」という宣言をします。それが ol 要素に記述されている itemscope と itemtype です。
itemscope には microdata を宣言する意味があり、値は必要ありません。itemtype は microdata の種類(タイプ)を示すために、その値を URL アドレスで指定します。
パンくずリストを表すタイプは http://schema.org/BreadcrumbList になります。
<ol itemscope itemtype="http://schema.org/BreadcrumbList"> ・・・ </ol>
itemtype には schema.org のリスト から当てはまる要素を探してその URL を記述します。
Thing → Intangible → ItemList → BreadcrumbList
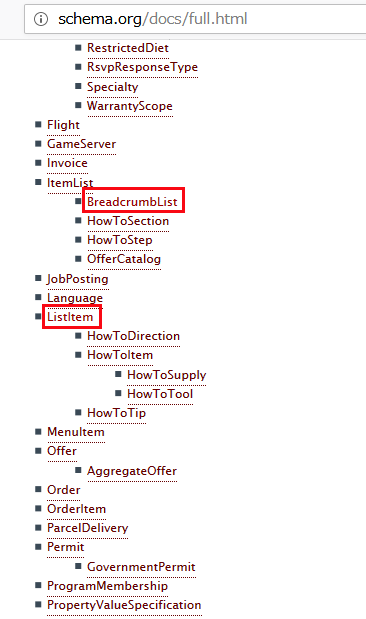
次に li 要素にリストを意味する itemtype="http://schema.org/ListItem" を記述し、そのページに記載されている Property の中から適切なものを選んで記述します。この場合は、itemprop="itemListElement" を記述します。
<ol itemscope itemtype="http://schema.org/BreadcrumbList">
<li itemprop="itemListElement" itemscope itemtype="http://schema.org/ListItem">
<a itemprop="item" href="../index.html"><span itemprop="name">Home</span></a>
<meta itemprop="position" content="1">
</li>
・・・
</ol>
そして以下の要素をマークアップします。
- URL(a 要素):パンくずリストが示す URL を itemprop="item" で指定します。
- ページ名(span 要素):パンくずに記載するページ名を itemprop="name" で指定します。
- パンくずリストの順番:itemprop="position" で指定します。パンくずリストの先頭から、1つ目ならcontent="1"、2つ目ならcontent="2"…のように数が増えていきます。この要素は、meta データを使用します。
microdata を使ったパンくずリストのサンプルは、http://schema.org/BreadcrumbList のページの下の方に example として掲載されています。
また、シンタックスとして JSON-LD や RDFa を使った記述例も掲載されています。
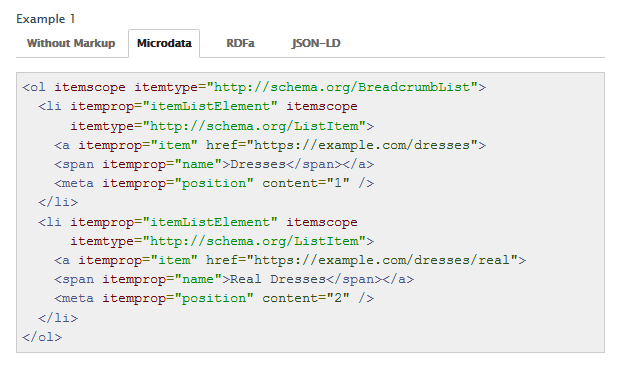
パンくずリストのテスト
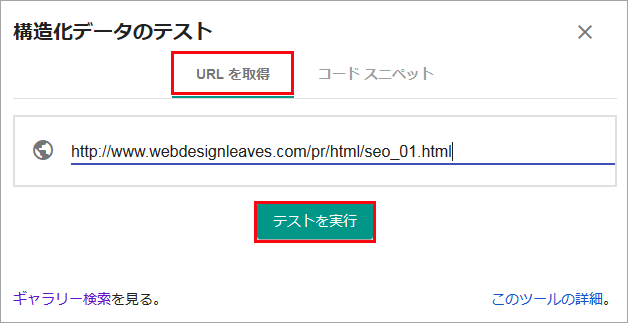
パンくずリストを正しく設置できたかどうかは、Google の提供している「構造化データテストツール」で確認することができるので、必ずエラーがないことを確認するようにします。
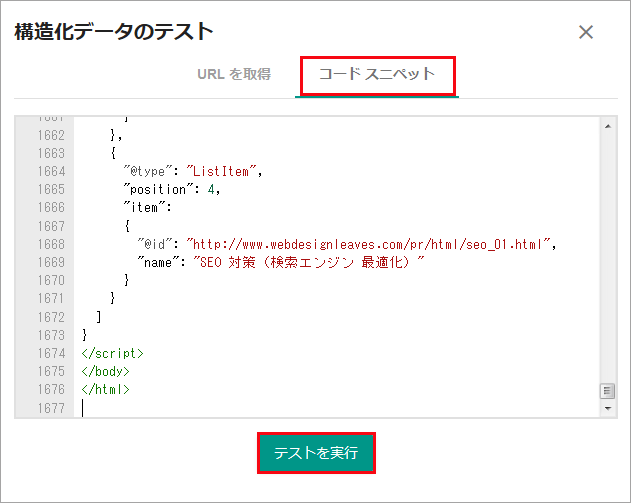
「構造化データテストツール」のページアクセスすると、以下のような画面が表示されるので、すでに公開されているページの場合は、「URLを入力」という欄にそのページの URL を入力して「テストを実行」をクリックします。
まだ公開していないページの場合は、「コードスニペット」をクリックして選択し、ページ全体の HTML を貼り付けて「テストを実行」をクリックします。
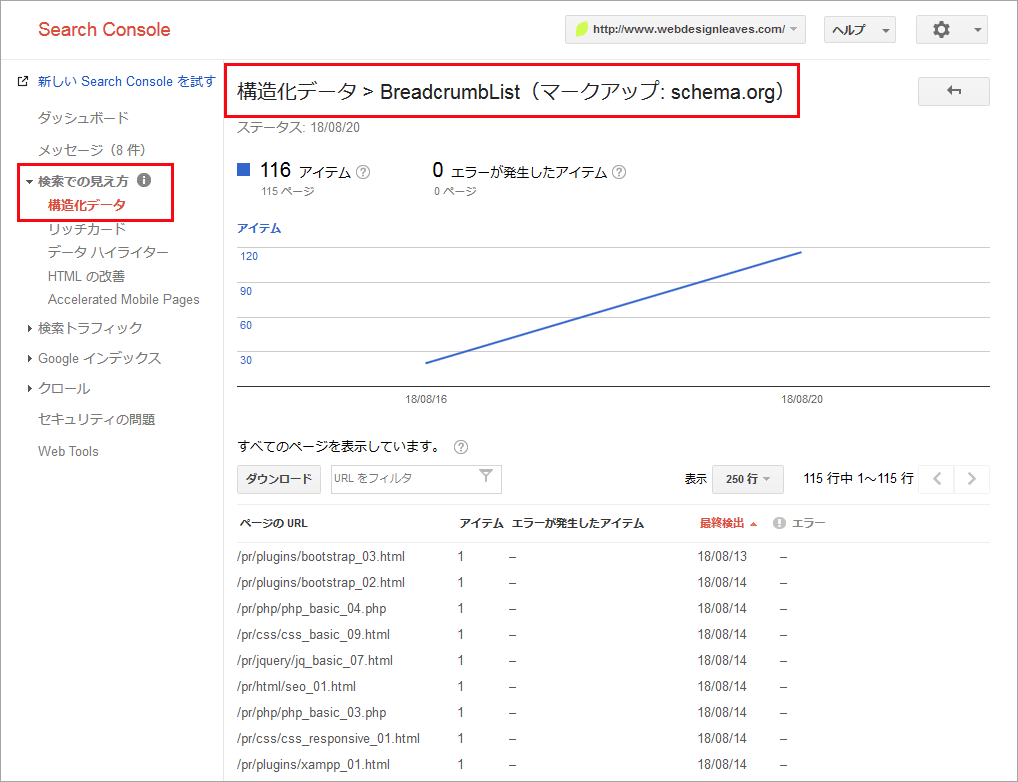
構造化データを使ったパンくずリストを設置後、しばらくすると、Search Console でパンくずリストが認識されているか(登録状況)を確認することができます。(このサイトの場合は5日後ぐらいで20ページほど登録され、約1週間後に 116 ページ登録されました。全てのページが登録されるにはある程度の時間がかかるようです。)
「検索での見え方」→「構造化データ」→表示されているデータタイプ「BreadcrumbList」をクリックします。
JSON-LD で構造化マークアップ
関連ページ:WordPress パンくずリストの作成/JSON-LD で構造化マークアップ
以下は schema.org のボキャブラリーを使った JSON-LD での構造化マークアップの例です。
JSON-LDは、前述の microdata のように既存のタグに追加することなく、ヘッダー内や </body> の直前などページのどこかに記述しておけば構造化データとして認識されます(パンくずリストの HTML は記述しておく必要があります)。
以下のように type 属性に application/ld+json を指定した script タグで JSON-LD フォーマットの宣言をまず行います。
script タグは head 内、body 内のどちらにでも記述できるので、記述場所は限定されません。
<script type="application/ld+json">...</script>
JSON では、波括弧({})の中に、1つまたは複数の Key と Value のペアを含めたものを記述していきます。
- Key と Value はコロン(:)で区切ります
- 左側に Key、右側に Value を記述し、それぞれをダブルクォーテーション(")で囲みます
- ペアを増やす場合はカンマ(,)を付けます
- 最後のペアの場合はカンマは必要ありません(付けません)
- 波括弧({})で囲んだ1つのまとまりを JSON オブジェクトと言います
Key の中でも、@context や @type など、「@」の付くものはキーワードと呼ばれ、良く使われるものとしては以下のようなものがあります。
- @Context:構造化データがどのような定義(ボキャブラリー)に基づくかを指定します
- @type:構造化するアイテムのタイプを指定します
- @id:リソースを一意に示す識別子でURLの部分を示す場合などに使用します
@context の value は基本的に "http://schema.org" を指定します(schema.org を使用する場合)。
@type には、パンくずリストの場合 "BreadcrumbList" を指定します。
キーワード以外の場合は、key にはプロパティ(属性)を、value にはその値を指定します。
パンくず部分のリストは "itemListElement" を使って記述していきます。パンくずは複数あるので、配列([])を使います。それぞれのタイプ(@type)は "ListItem" になります。
"position" は階層を意味し、一番上の階層(トップページまたはパンくずリストの先頭のページ)は「1」で、階層が深くなるごとに「2」「3」「4」と値(整数で指定)が増えていきます(※)。
それぞれのパンくずが表す URL と名前は item を使って、"@id" にはそのページの URL(またはパス)を、"name" にはそのページの名前(タイトル)を記述します。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "BreadcrumbList",
"itemListElement":
[
{
"@type": "ListItem",
"position": 1,
"item":
{
"@id": "https://www.webdesignleaves.com/",
"name": "Home"
}
},
{
"@type": "ListItem",
"position": 2,
"item":
{
"@id": "https://www.webdesignleaves.com/pr/",
"name": "Web制作資料"
}
},
{
"@type": "ListItem",
"position": 3,
"item":
{
"@id": "https://www.webdesignleaves.com/pr/html/",
"name": "HTML"
}
},
{
"@type": "ListItem",
"position": 4,
"item":
{
"@id": "https://www.webdesignleaves.com/pr/html/seo_01.html",
"name": "SEO 対策(検索エンジン 最適化)"
}
}
]
}
</script>
パンくずリストのサンプルは、http://schema.org/BreadcrumbList のページの下の方に example として、それぞれ Microdata、RDFa、JSON-LD のタブに掲載されています。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "BreadcrumbList",
"itemListElement":
[
{
"@type": "ListItem",
"position": 1,
"item":
{
"@id": "https://example.com/dresses",
"name": "Dresses"
}
},
{
"@type": "ListItem",
"position": 2,
"item":
{
"@id": "https://example.com/dresses/real",
"name": "Real Dresses"
}
}
]
}
</script>
以下は、HTML と CSS の記述例です。この例の場合は、そのページ自体はパンくずリストに含めていません。そのページを含めるかどうかは、使い勝手や SEO 的なことを考慮して判断する必要があると思います。
<div class="breadcrumbs clearfix">
<ul>
<li><a href="../../">Home</a></li>
<li><a href="../">Web制作資料</a></li>
<li><a href="index.html">HTML</a></li>
</ul>
</div>
::after を使って「>」を表示するようにしています。最後の要素は何も表示しないようにしています。
.breadcrumbs ul {
list-style-type: none;
}
.breadcrumbs li {
display: inline-block;
}
.breadcrumbs li::after {
content: " > ";
}
.breadcrumbs li:last-child::after {
content: "";
}
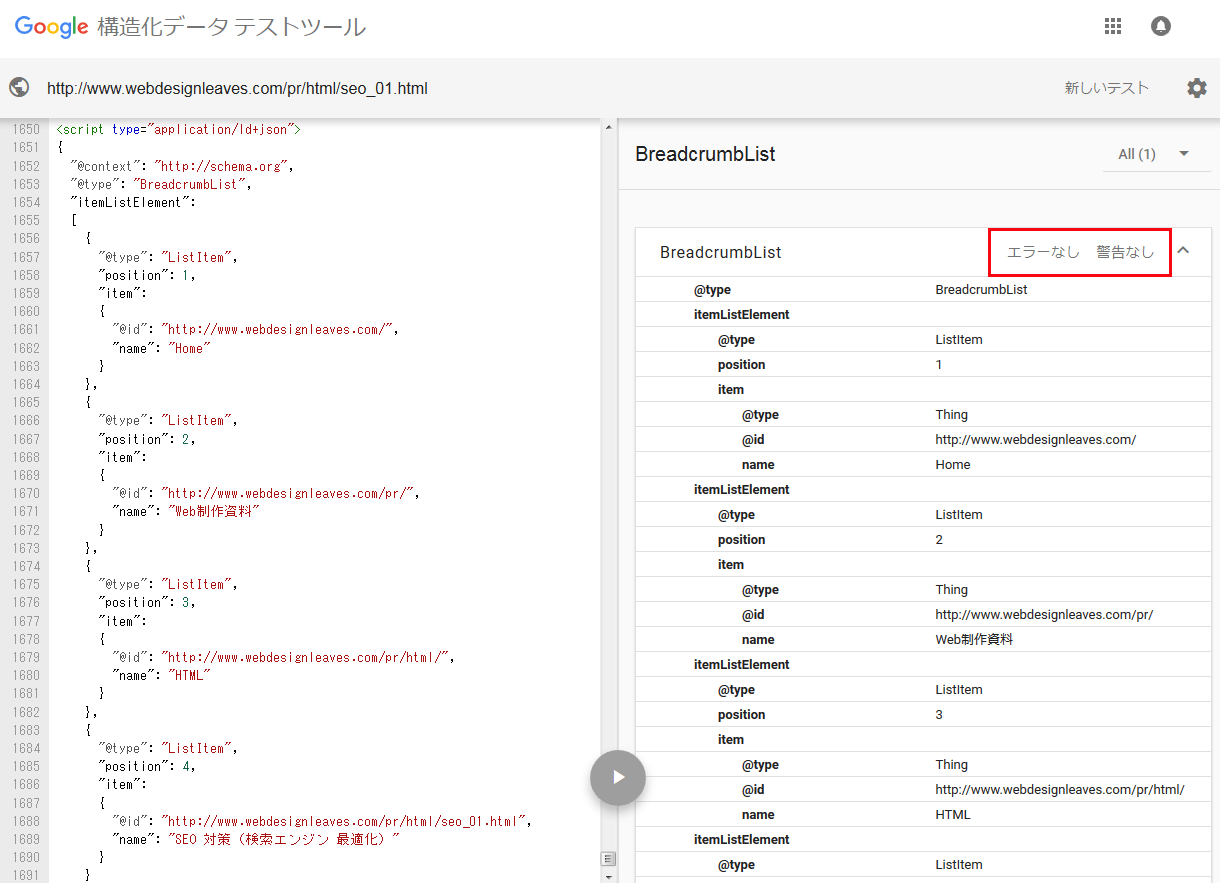
以下は、「構造化データテストツール」でのテスト結果の例です。エラーや警告がなければOKです。
noindex,nofollow,noarchive
meta 要素の name 属性に robots を指定するおとで、検索エンジンのクローラに対して、ページの処理を指示する事ができます。
但し、この指定はすべての検索エンジンに対して有効ではなく、この情報を参照しない検索エンジンに対しては効果がないようです。
以下のように content 属性に noindex、nofollow、noarchive などの値を指定します。複数の値を指定する場合は、カンマ区切りで指定します。
<meta name="robots" content="noindex"> <meta name="robots" content="nofollow"> <meta name="robots" content="noarchive"> <meta name="robots" content="noindex,nofollow"> <meta name="robots" content="noindex,follow"> <meta name="robots" content="none">
noindex
noindex は、Web ページをインデックス登録させたくない場合に使います。検索エンジンに見せる必要がないページに noindex を設定すれば、検索結果に表示されないようになります。
noindex が設定されたページは、検索結果には表示されなくなりますが、検索エンジンによるクローリングは実行されます(ロボットのアクセスをブロックするわけではありません)。
これを適切に使えば、サイト全体の評価を良くすることができる場合があるとのことです。例えば、404エラーページは検索結果に表示される必要はないので、noindex を設定しておく等があります。
<meta name="robots" content="noindex">
参考ページ:
noindex を使用して検索インデックス登録をブロックする
Robots メタタグと X-Robots-Tag HTTP ヘッダーの仕様
nofollow
nofollow を設定すると、検索エンジンが Web ページ内のリンク先(a タグで指定された別のページ)をたどらないようにすることができます。これにより、ロボットに余計なリソースを使わさせないことができ、また、リンク先の Web サイトが信用できない場合などにリンクを通してページ評価(PageRank)を受け渡さなくなります。
<meta name="robots" content="nofollow">
noindex を設定しているページでは、大方の場合はページ評価の受け渡しは不要なので、nofollow が合わせて指定する場合が多いです(例外もあります)。両方をカンマ区切りで指定することができます。
<meta name="robots" content="noindex,nofollow">
none と記述しても noindex,nofollow と同じ意味になります。
<meta name="robots" content="none">
サイト内の各ページへのリンクを表示している「ユーザー向けサイトマップ」などで、そのページは検索結果で表示したくないけれども、そのリンクをクローラにたどらせたい場合には noindex と follow の組み合わせが有効です。
<meta name="robots" content="noindex,follow">
個別のリンク(a 要素) rel="nofollow"
nofollow はページ内の全てのリンクに対する制御ですが、個別のリンク(a 要素)に対して使う場合は、rel="nofollow" になります。
nofollow を設定して、検索エンジンやロボットにページ上の個々のリンク全てについて追跡、クロールしないよう指示する代わりに、rel="nofollow" は特定のリンクをクロールしないようにする場合に使用します。
<a href="signin.php" rel="nofollow">sign in</a>
nofollow の使用に関する Google のポリシー
Google が推奨している nofollow の使い方は以下の3つです。
- 信頼できないコンテンツ(サイト)へのリンク
- 有料リンク(有料広告へのリンク)
- クロールの優先順位を最適化
以下は「特定のリンクに対して rel="nofollow" を使用する」からの抜粋です。
- 信頼できないコンテンツ: サイトのリンク先のページのコンテンツを保証できない、あるいは保証したくない場合(リンク先が信頼性のないユーザー コメントやゲストブック エントリの場合など)は、このようなリンクを除外します。これにより、サイトが不正行為者のターゲットになることを阻止でき、不正なウェブサイトの PageRank に貢献しないようにできます。特に、コメント スパムでは、特定のコンテンツ管理システムやブログ サービスで信頼できないリンクが追跡されていないことがわかると、それらを攻撃の対象から除外することが考えられます。信頼のおける投稿者を尊重したいのであれば、長期にわたって質の高い投稿を続けているメンバーやユーザーが投稿したリンクから nofollow 属性を自動または手動で削除することもできます。
- 有料リンク: Google の検索結果のサイト ランキングでは、有料サイトにリンクするサイトについての分析結果も一部考慮されています。有料リンクによって検索結果に影響が生じたりユーザーに悪影響が及んだりしないように、ウェブマスターは有料リンクに nofollow を使用することをおすすめします。検索エンジン ガイドラインでは、有料リンクであることをコンピュータで識別できる必要があるとしています。これは、ウェブ上かどうかを問わずユーザーが金銭関係の有無を知りたいのと同じです(新聞の一面広告に「広告」という見出しが付けられているなど)。有料リンクに対する Google の方針について詳しくは、こちらをご覧ください。
- クロールの優先順位: 検索エンジン ロボットは、メンバーとしてフォーラムにログインすることも登録することもできません。このため、Googlebot で「ご登録はこちらから」 や「ログイン」のリンクをたどる必要性はありません。このようなリンクで nofollow を使用すれば、他に Google インデックスへの登録を優先したいページが Googlebot でクロールされるようになります。しかしながら、わかりやすいナビゲーション、ユーザーや検索エンジンにわかりやすい URL など、体系的にサイトを構築するほうが、リンクに nofollow 属性を設定してクロールの優先順位を付けるより、はるかに効果的にリソースを活用できます。
関連ページ:コメントスパムを防止する方法
noarchive
Google などの検索結果には、クローラが取得したキャッシュを閲覧するリンクがあります。noarchive を設定すると、そのキャッシュへのリンクを表示させないことができます。EC ショップや会員制のサイトなどで使用されます。
<meta name="robots" content="noarchive">
参考ページ:METAタグ活用完全ガイド
Google インデックス 登録・申請
作成したページ(サイト)を Google の検索結果に表示されるようにするには、Google がそのページ(サイト)を認識し、Google の検索エンジン(データベース)に登録される必要があります。
Google のデータベースに登録されることを「Google にインデックスされる」と言います。
通常は作成後しばらくすると、Google が勝手に登録してくれますが、時間がかかる場合などもあり、そのような場合は、Google にインデックスの登録(クロール)を申請することもできます。
新規作成の場合だけではなく、ページを更新したりタイトルを変更した後にも申請すると早く反映される可能性が高くなります。但し、再クロールを何度もリクエストしたり、複数の方法を使用したりしても、クロールが速くなるわけではありません。
以下は「URL の再クロールを Google にリクエストする」からの抜粋です。
サイトにページを追加したり変更を加えたりした場合は、ここに記載されている方法を使用して、インデックスへの登録(または再登録)を Google にリクエストできます。
一般的なガイドライン
- 同じ URL に対して再クロールを何度もリクエストしたり、複数の方法を使用したりしても、クロールが速くなるわけではありません。
- クロールには数日から数週間かかることがあります。しばらくお待ちになってから、インデックス ステータス レポートまたは URL 検査ツールを使用して進行状況をモニタリングしてください。
- これらの方法を使用した個々の URL の送信には、上限があります。
- それぞれの方法の応答時間は、ほぼすべて同じです。
URL のクロール(インデックス登録)を Google にリクエストするには「Fetch as Google ツール」を使用します。使い方等については以下の関連項目ページをご覧ください。
※このツールは 2019/03/28以降は利用できなくなるので、代わりに新しい URL 検査ツールを利用します。
URL 検査ツール
URL 検査ツールを使うと Google のインデックスに登録されたページの情報を確認することができ、インデックス登録で問題がある場合はその内容を確認することができます。
但し、この機能は新しい Search Console のベータ版の一部なので、新しい Search Console に切り替えて確認します。
Search Console にアクセスして対象のサイト(プロパティ)を選択後、の左上の「新しい Search Console を試す」をクリックすると、新しい Search Console が表示されます。
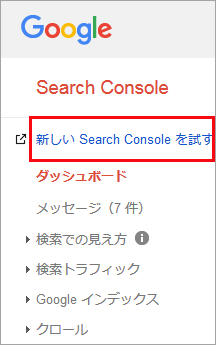
Search Console 内のページの上部にある検索バーに完全な URL を入力して Enter キーを押すと検査が開始されます。
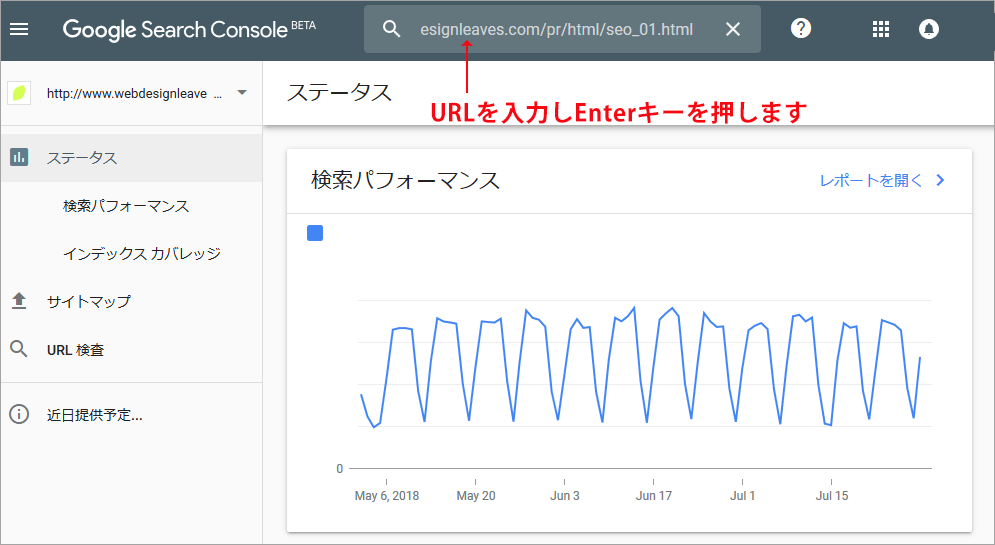
少しすると結果が表示されるので確認します。以下は問題がない場合の表示例です。
Search Console を以前のバージョンに戻すには、左下の「以前のバージョンに戻す」をクリックします。
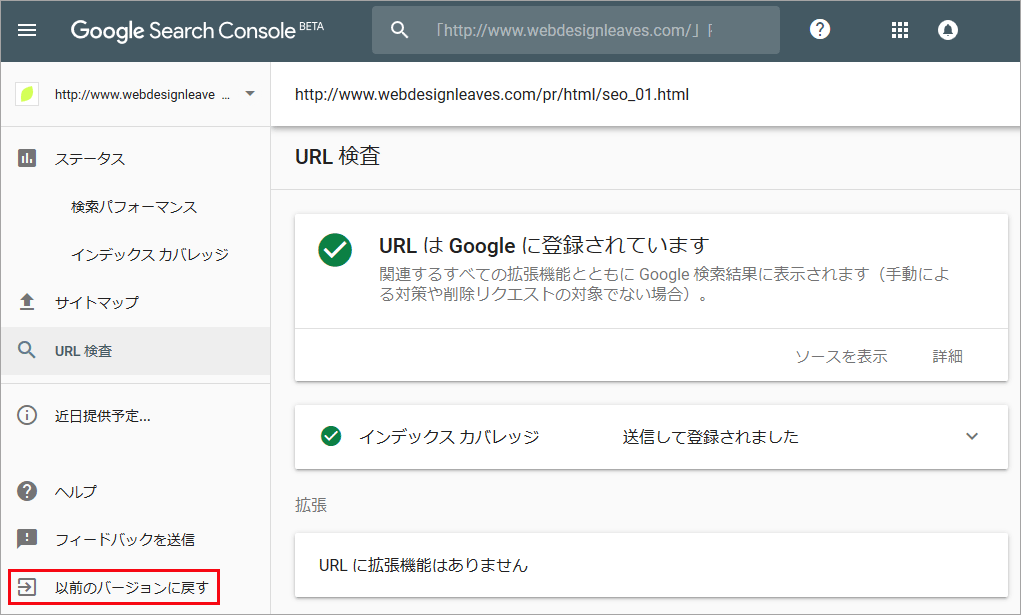
URL のクロールのリクエスト
Search Console にアクセスして左上のプルダウンから対象のサイト(プロパティ)を選択後、「URL 検査」をクリックします。
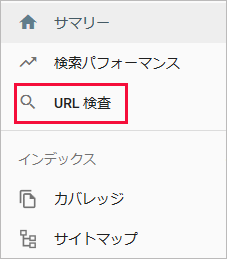
上部の入力欄にクロールをリクエストしたい URL を入力して Enter キーを押します。
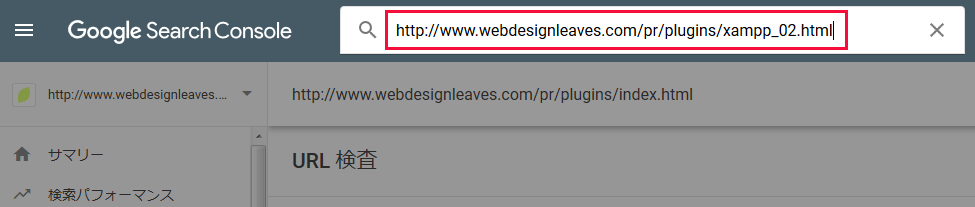
「Google インデックスからデータを取得しています」と表示された後に、現在登録されているかが表示され、「インデックス登録をリクエスト」と言うリンクがあるので、それをクリックします。
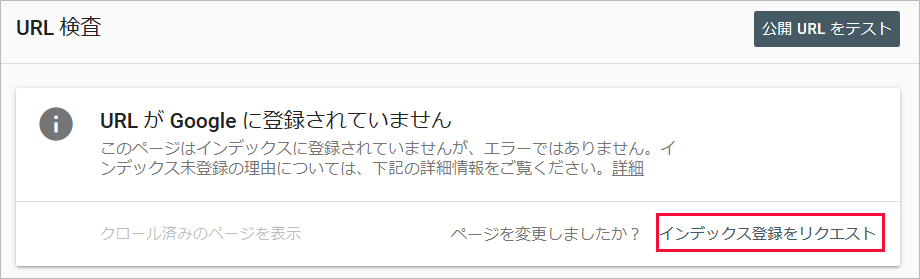
「公開 URL がインデックスに登録可能かどうかをテストする」という以下のようなメッセージが表示されます。
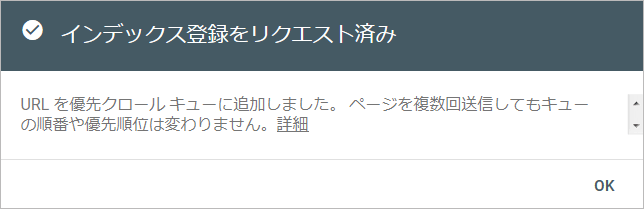
登録が完了すると、以下のように「インデックス登録をリクエスト済み」と表示されます。
SEO 外部対策
外部対策は、外部のウェブサイトから自分のウェブサイトへリンクしてもらう(被リンクを集める)ための作業(対策)が基本になります。
「被リンクは意味がなくなった」と言われることがありますが、現時点(2018年5月)でも被リンクは重要な要素です。
但し、以前は被リンクが多いほど良いサイトと評価されていましたが、現在はどんな被リンクでも良いという訳ではありません。出来るだけ質の高いサイトから不自然ではないリンクを得ることが大切です。
外部対策は、質の高いサイトを作ることによってサイトの評価を高めて、他の質の高いサイトから自然なリンクを得ることです。
被リンクの確認
被リンクの数や種類は、Google Search Console へログインして「検索トラフィック」→「サイトへのリンク」で確認することができます。
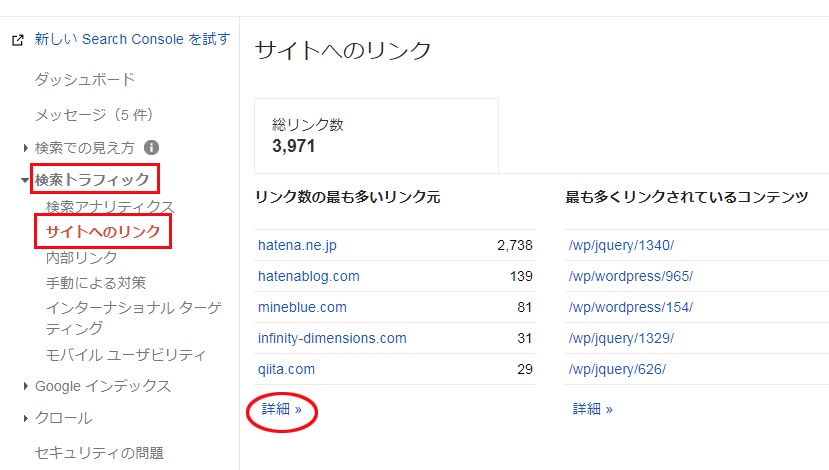
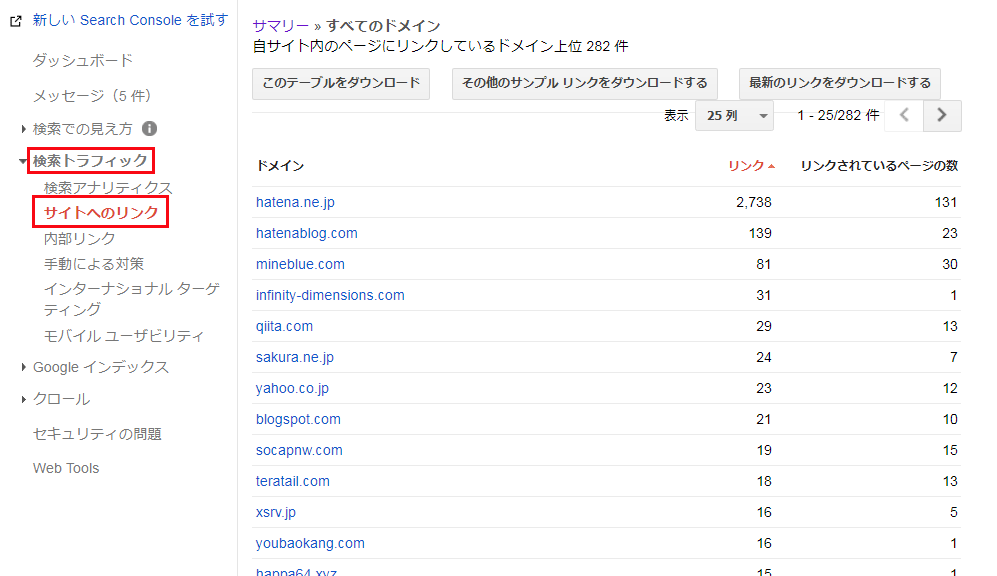
「詳細」をクリックすると、リンク元のドメイン全てを確認することができます。また、リンク元のドメインをクリックすると更に詳細が確認できます。
ペナルティの確認
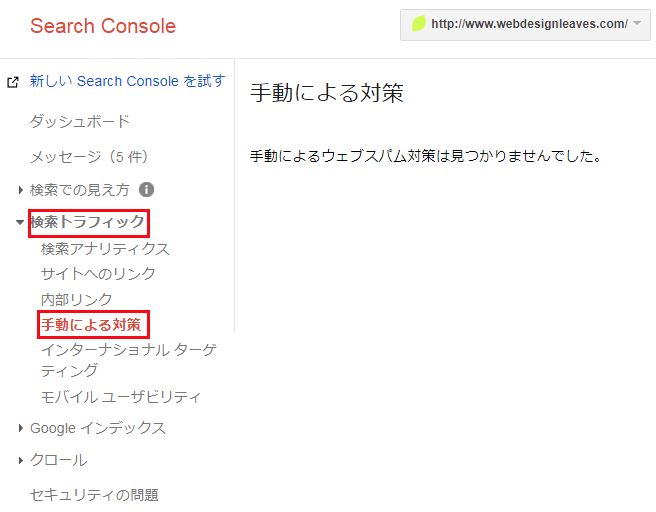
ペナルティを受けているかどうかは、Google Search Console へログインしてダッシュボード画面で確認することができます(警告マークのついた文章が表示されます)。
詳細を確認するには、左メニューから「検索トラフィック」→「手動による対策」で確認できます。
以下のように「手動によるウェブスパム対策は見つかりませんでした。」とあれば、ペナルティは受けていません。
不適切な被リンク
以下は Google が不適切としている被リンク(不自然なリンク)について Google Search Console ヘルプの「リンク プログラム」からの抜粋です。悪質と判定された被リンクは、ペナルティを受ける可能性があります。
PageRank や Google 検索結果でのサイトのランキングを操作することを意図したリンクは、リンク プログラムの一部と見なされることがあり、Google のウェブマスター向けガイドライン(品質に関するガイドライン)への違反にあたります。これには、自分のサイトへのリンクを操作する行為も、自分のサイトからのリンクを操作する行為も含まれます。
検索結果でのサイトのランキングに悪影響を与える可能性のあるリンク プログラムとして以下のようなものが挙げられています。
- PageRank を転送するリンクの売買。これには、リンク、またはリンクを含む投稿に対する金銭のやり取り、リンクに対する物品やサービスのやり取り、商品について書いてリンクすることと引き換えに「無料」で商品を送ることなどが含まれます。
- 過剰なリンク交換、または相互リンクのみを目的としてパートナー ページを作成すること。
- アンカー テキスト リンクにキーワードを豊富に使用した、大規模なアーティクル マーケティング キャンペーンやゲスト投稿キャンペーン。
- 自動化されたプログラムやサービスを使用して自分のサイトへのリンクを作成すること。
また、サイトの所有者が編集時にページに配置したリンクではないリンクや保証していないリンクを「不自然なリンク」と呼んで、以下のような例(Google のガイドラインへの違反にあたる不自然なリンク)を挙げています。
- PageRank を転送するテキスト広告。
- PageRank を転送するリンクを含む記事に対して支払いが行われるアドバトリアルやネイティブ広告。
- 他のサイトに配布される記事やプレス リリース内の最適化されたアンカー テキスト リンク
- 質の低いディレクトリやブックマーク サイトのリンク。
- さまざまなサイトに分散するウィジェットに埋め込まれたリンク。
- さまざまなサイトのフッターに分散して幅広く埋め込まれたリンク。
- フォーラムでのコメントにおいて、投稿や署名の中に含まれる作為的なリンク。
業者にお金を支払ってリンクを貼ってもらったり、リンク用に作ったいい加減なサイトからのリンクは避けた方が良いでしょう。
PageRank
ページランク(Pagerank)とは Google の検索エンジンが Web ページを判定(評価)する際に指標となるもので、被リンク数とその質などによって決定されているようです。
以前はブラウザのツールバーでページランクを確認できましたが、現在はその情報は公開されていません。但し、外部公開を停止しただけで、Google のアルゴリズムとしては依然として機能しているようです。
また、以前はリダイレクト(転送)の種類により、ページランクを渡したりそうでなかったりすると言われていましたが、現在(2015年以降)はどのリダイレクト(301、302)でもページランクは転送先に渡されるようです。
ページランクを確認することはできませんが、Open Site Explorer(OSE)を使うとドメインやページの外部評価を確認できるようです。但し、無料で使用できるのは1日2回までのようです。
Open Site Explorer を使って表示される結果の「DOMAIN AUTHORITY」と「PAGE AUTHORITY」の指標がそれぞれドメイン自体の外部評価の高さ、ページの外部評価の高さを示しています。
効果的(有効)な被リンク
ユーザーに評価されているコンテンツを Google(検索エンジン)は評価します。ユーザーに満足されるような質の高いコンテンツを持つサイトが質が高いサイトとなります。
そのような質の高いサイトからの被リンクが効果的な被リンクと言えます。
以下は再度 Google Search Console ヘルプの「リンク プログラム」からの抜粋です。
他のサイトから自分のサイトへの高品質で関連性の高いリンクを作成してもらう最善の方法は、インターネット コミュニティで自然に人気を獲得する、関連性の高い独自のコンテンツを作成することです。
良質なコンテンツを作成すると、それが利益につながります。
リンクは編集者による人気投票のようなもので、役立つコンテンツの数が多いほど、誰かがそのコンテンツが自分のサイトのユーザーにとって役立つことに気付き、リンクを作成してもらえる可能性が高くなります。
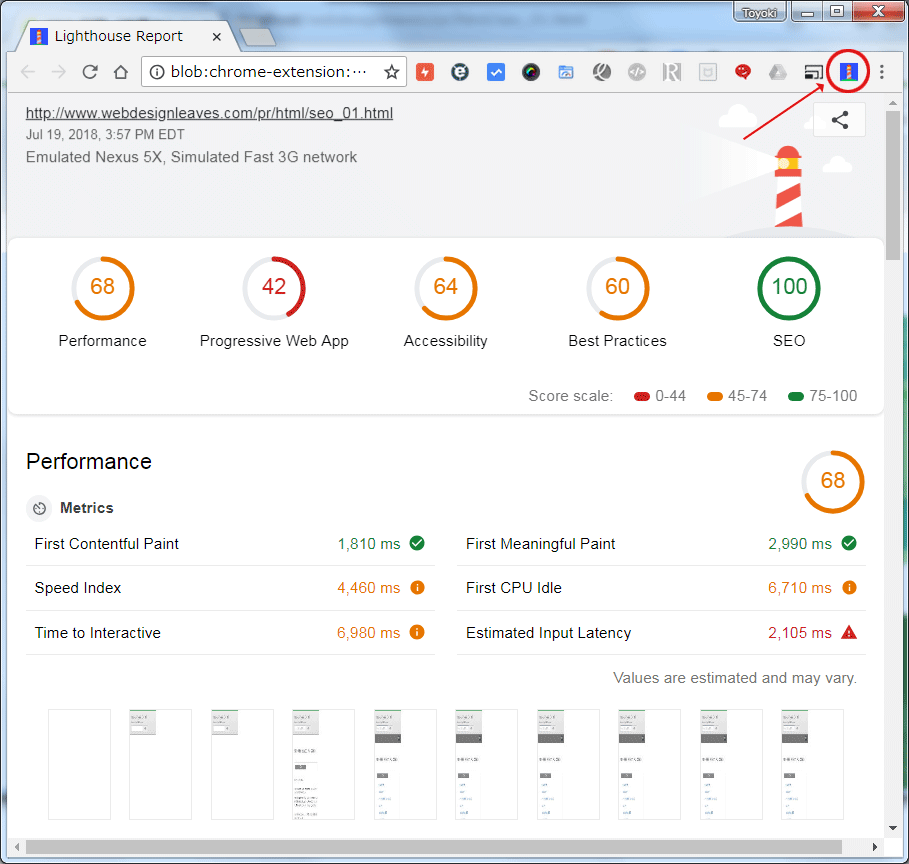
Lighthouse Chrome 拡張機能
Chrome の拡張機能 Lighthouse に SEO の監査項目が追加されました(2018年2月)。SEO に関するチェック項目は多くないようで、どのぐらい役に立つかは微妙ですが、ページの妥当性をチェックしてくれます。
Lighthouse Chrome 拡張機能に追加された SEO カテゴリのご紹介(ウェブマスター向け公式ブログ)
使い方は Chrome の拡張機能を追加するだけです。以下のページに詳細があります。
Lighthouse によるウェブアプリの監査(Tools for Web Developers )
以下は上記「ウェブマスター向け公式ブログ」からの抜粋です。
Lighthouse は、ウェブページの品質向上に役立つよう開発された、オープンソースの自動化されたツールです。サイトのパフォーマンス、アクセシビリティ、プログレッシブ ウェブアプリ(PWA)対応状況などについての確認でき、サイトの品質を向上させるための具体的な対策を提示します。デベロッパーの皆様が「暗礁に乗り上げないようにする」ことを目的としているため、「Lighthouse(灯台)」と名付けられました。
Lighthouse 内の SEO カテゴリでは、ウェブページの基本的な「SEO ヘルスチェック」を実行できます。その結果、デベロッパーやウェブマスターの皆様にウェブページで改善可能な箇所を見つけていただけるようになっています。Lighthouse は Chrome ブラウザでローカルに実行されるため、ステージング環境でも、公開中のページでも、認証が必要なページでも、同じように SEO 監査を実行できます。
以下はこのページを調べた結果です。パフォーマンス、アクセシビリティ、プログレッシブ ウェブアプリ(PWA)対応状況などに多数の問題が指摘されているのがわかります。SEO に関してはあまり詳細にはチェックされないようです。
ページの表示速度を評価してくれるツール PageSpeed Insights もページの改善に役立つツールです。
構造化データ マークアップ
構造化データ(Structured Data)とは、HTMLで書かれた情報が何を意味するのかを、検索エンジンやその他のクローラーに理解できるようタグ付け(メタデータとしてマークアップ)したものです。
現状では検索エンジンはテキスト情報であることは認識ができても、そのテキスト情報の意味を正確に認識することが難しいため、検索エンジンが Web サイトの構造や意味を理解できるように構造化データを使用します。
<div>イグザンプル株式会社</div>
<div itemscope itemtype="http://schema.org/Corporation"> <span itemprop="name">イグザンプル株式会社</span> </div>
構造化データには、以下のようなボキャブラリー(どのような情報を構造化データに含めるかの定義)があります。代表的なものとしては schema.org があり、ここではこの schema.org のボキャブラリーを使っていきます。
- schema.org
- data-vocabulary.org
- その他
Google 単独で策定していた data-vocabulary.org は、プロジェクトとしての開発はすでに終了していて、今後は schema.org に置き換わることになるとのことです。
Facebook などの設定で使用する OGP(Open Gragh Protocol)もボキャブラリーの1つです。
またシンタックス(文法・記述方法)には、以下のようなものがあります。Google が推奨しているのは JSON-LD ですが、どれを使ってもいいことになっているようです。
ちなみに OGP は RDFa というシンタックスを用いて記述されています。
schema.org
schema.org は Google, Yahoo, Microsoft の3社で策定をしているボキャブラリーの規格です。
schema.org のボキャブラリーは、タイプ(Type)で構成されています。各タイプにはそれぞれ独自のプロパティ(Property)があり、その属性を設定するために使用することができます。
schema.org でマークアップするにはタイプと プロパティを指定します。
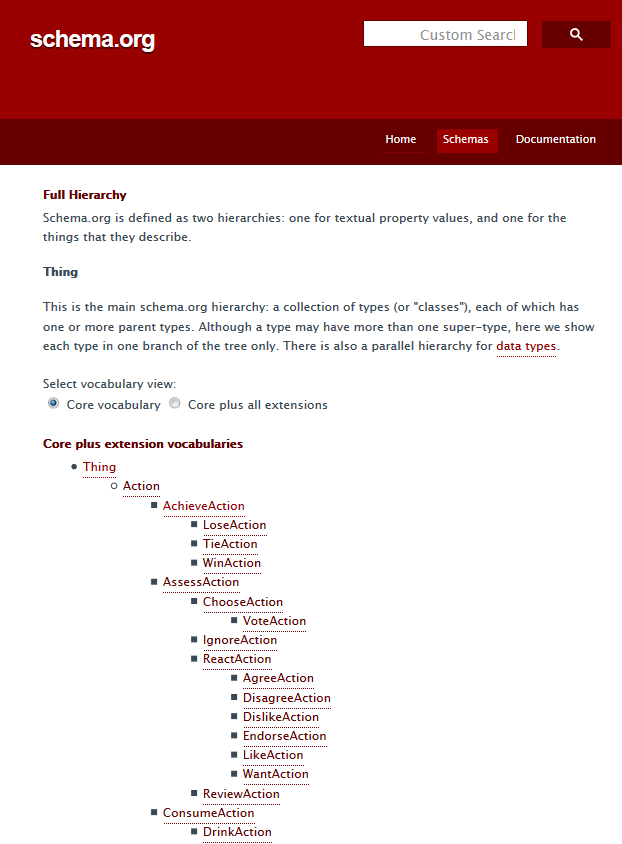
schema.org にどのようなタイプがあるかは以下のリンクから確認することができます。
タイプのトップの階層は Thing(最も包括的なタイプ・型)になっていて、その下の階層には以下のようなタイプがあります。
- Action
- CreativeWork
- Event
- Intangible
- Organization
- Person
- Place
- Product
microdata
microdata は HTML タグの中に記述し、ページに記述されている HTML 要素に情報を追加していきます。既存の HTML 要素に構造化データ用の属性を追加したり、追加の meta タグをコンテンツの子要素として追加したりします。
まず構造化データを表す最初のタグで、使用するボキャブラリ(シンタックス)とタイプを宣言します。
itemscope には microdata(シンタックス)を宣言する意味があり、値は必要ありません。itemtype は microdata の種類(タイプ)を示すために、その値を URL アドレスで指定します。
例えば「会社」をマークアップする場合、この例では、itemtype に http://schema.org/Corporation を指定します。Corporation の他にも LocalBusiness など色々なタイプのものがあります。
<div itemscope itemtype="http://schema.org/Corporation">...</div>
次にプロパティを設定していきます。
Corporation のページ(http://schema.org/Corporation)で、そのタイプに使えるプロパティを確認することができます。
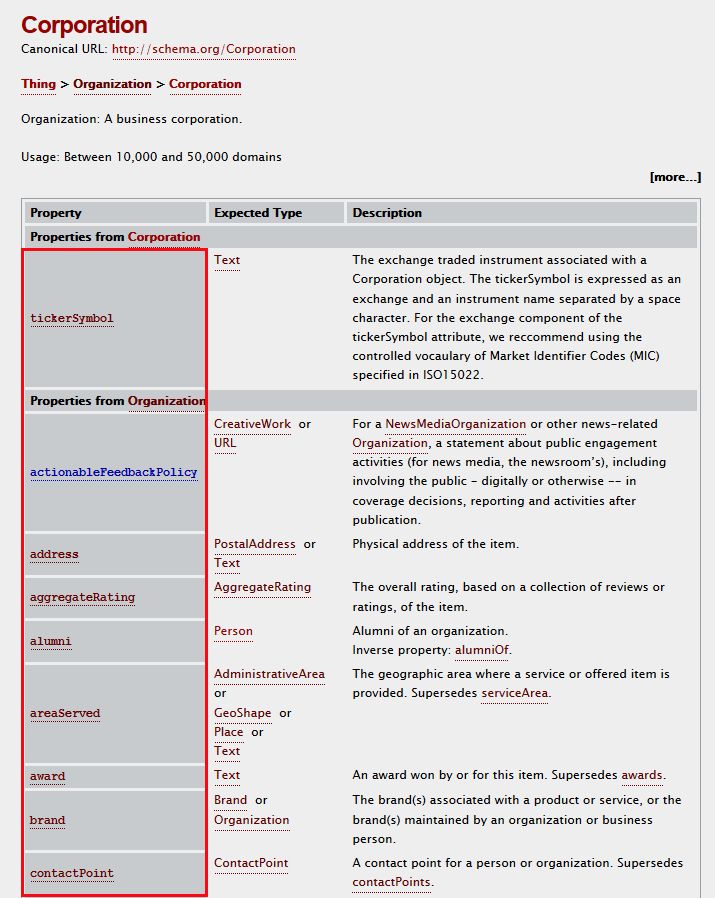
プロパティの記述は、最初にシンタックスを宣言したタグより下層のタグでプロパティを指定します。
プロパティの指定方法は itemprop="プロパティ名" とします。以下は会社名(itemprop="name")を指定した例です。
<div itemscope itemtype="http://schema.org/Corporation"> <span itemprop="name">イグザンプル株式会社</span> </div>
以下は住所( itemprop="address" )、電話番号(itemprop="telephone")、URL(itemprop="URL")も指定した例です。
※構造化するデータでない文字列(会社名:や 住所:など)は microdata を使ったタグではマークアップしないようにします。
<div itemscope itemtype="http://schema.org/Corporation"> 会社名:<span itemprop="name">イグザンプル株式会社</span> 住所:<span itemprop="address" >東京都港区芝公園4丁目1-2-3</span> 電話番号:<span itemprop="telephone" content="+81345678765">03-4567-8765</span> URL:<span itemprop="URL">http://www.example.com/</span> </div>
電話番号の部分は、ユーザーには一般的な表記の 03-4567-8765 を表示していますが、構造化データとして検索エンジンには国際電話番号表記の +81345678765 を指定しています。
構造化データは、上記の例のようにタイプ(http://schema.org/Corporation)を親として、プロパティ(nameやaddressなど)を子とする親子関係の構造(入れ子構造)になっています。
また、プロパティによっては、文字列(Text)ではなくタイプを指定して、子どもの子ども(孫)を持つことができ、その孫によって子どもをさらに詳しく説明することができます。
http://schema.org/Corporation の address プロパティの右の Expect Type の項には PostalAddress or Text と記載されています。
これは address プロパティには PostalAddressというタイプか、または文字列を指定することができるという意味で、address をさらに構造化して詳しく記述することが可能であることを意味します。
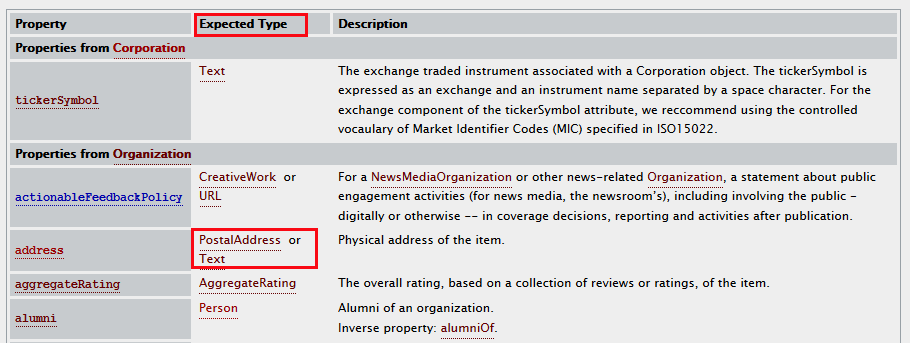
※プロパティを指定しているタグにタイプを指定する場合(新たに入れ子構造を作る場合)は、再度 itemscope、itemtype の宣言が必要になります。
PostalAddress タイプを、http://schema.org/PostalAddress のページで確認すると、プロパティとして "postalCode" や "addressRegion" などがあるので、これらのプロパティの値を指定してみます。
<div itemscope itemtype="http://schema.org/Corporation">
会社名:<span itemprop="name">イグザンプル株式会社</span>
住所:<span itemprop="address" itemscope itemtype="http://schema.org/PostalAddress">
<span itemprop="postalCode">105-0011</span>
<span itemprop="addressRegion">東京都</span>
<span itemprop="addressLocality">港区</span>
<span itemprop="streetAddress">芝公園4丁目1-2-3</span>
</span>
電話番号:<span itemprop="telephone" content="+81345678765">03-4567-8765</span>
URL:<span itemprop="URL">http://www.example.com/</span>
</div>
構造化データテストツール
構造化データは、Google の提供している「構造化データテストツール」で確認することができるので、必ずエラーがないことを確認するようにします。
JSON-LD
JSON-LD は、JSON を使って Linked Open Data を表現するために策定を進めてきた仕様で、これにより文字列に意味を持たせることが可能になりました。
JSON-LD は、表示される文字列(HTML)とは別の場所に記述します。言い換えると、同じ内容(記述方法は異なりますが)を HTML 本文中と JSON-LD フォーマットとで書くことになります。
microdata は、該当する HTML 部分に対して、必要に応じて div 要素、span 要素、meta 要素を記述してその属性値を使って構造化を示すため、HTML が複雑になり DOM にも変更が生じたり、CSS や JavaScript への影響が発生する場合があります。
JSON-LD の場合は、そのような制限はなく、当該ページ中のどこにでも記述することができ、1箇所にまとめることもできます。該当部分の HTML はそのままで、CSS や JavaScript への影響の心配も不要です。
記述する場所は、head 内に記述することもでき、body 内や body の閉じタグの直前に記述することもできます。
JSON-LD の記述方法
以下のように type 属性に application/ld+json を指定した script タグで JSON-LD フォーマットの宣言をまず行います。
script タグは head 内、body 内のどちらにでも記述できるので、記述場所は限定されません。
<script type="application/ld+json">...</script>
JSON では、波括弧({})の中に、1つまたは複数の Key と Value のペアを含めたものを記述していきます。
- Key と Value はコロン(:)で区切ります
- 左側に Key、右側に Value を記述し、それぞれをダブルクォーテーション(")で囲みます
- ペアを増やす場合はカンマ(,)を付けます
- 最後のペアの場合はカンマは必要ありません(付けません)
- 波括弧({})で囲んだ1つのまとまりを JSON オブジェクトと言います
<div class="company-info">
<h3 class="company-name">会社名:イグザンプル株式会社</h3>
<p class="address">住所:105-0011 東京都港区芝公園4丁目1-2-3</p>
<p class="tel">電話番号:03-4567-8765</p>
<p class="url">URL:<a href="http://www.example.com/">http://www.example.com/</a></p>
</div>
・・・
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "イグザンプル株式会社",
"address": "東京都港区芝公園4丁目1-2-3",
"telephone": "+81345678765",
"URL": "http://www.example.com/"
}
</script>
Key の中でも、@context や @type など、「@」の付くものはキーワードと呼ばれ、良く使われるものとしては以下のようなものがあります。
- @Context:構造化データがどのような定義(ボキャブラリー)に基づくかを指定します
- @type:構造化するアイテムのタイプを指定します
- @id:リソースを一意に示す識別子でURLの部分を示す場合などに使用します
@context の value は基本的に "http://schema.org" を指定します(schema.org を使用する場合)。
@type では、構造化するアイテムのタイプを http://schema.org/docs/full.html から探します。
キーワード以外の場合は、key にはプロパティ(属性)を、value にはその値を指定します。どんなプロパティが利用できるのかは、schema.org のサイトで確認できます。
親子関係をもたせる場合(Embedding)
JSON オブジェクトに親子関係を持たせることができます。value にさらに JSON オブジェクトを埋め込むことを Embedding(エンベッディング)と言います。
書き方は、親子にしたい key の value に { } を記述し、タイプを指定したら、必要な key と value のペアを入力します。
http://schema.org/Corporation の address プロパティは PostalAddress タイプという子どもを持つことができます。
以下の例の場合、address プロパティが key、PostalAddress タイプの JSON オブジェクトが value となります(JSON オブジェクトは { } で囲む決まりになっています)。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "イグザンプル株式会社",
"address": {
"@type": "PostalAddress",
"postalCode" : "105-0011",
"addressRegion": "東京都",
"addressLocality": "港区",
"streetAddress": "芝公園4丁目1-2-3"
},
"telephone": "+81345678765",
"URL": "http://www.example.com/"
}
</script>
embed された JSONオ ブジェクトの中では、@context によるボキャブラリーの宣言は省略可能なようです。
value に複数の値(配列)
value に複数の値を指定する場合は、配列(Array)を使います。value に複数の値を入れる場合は、角カッコ[ ]でくくり、それぞれの値はカンマ(,)で区切ります。
以下は、employeeプロパティに2人を指定した例です。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "イグザンプル株式会社",
"address": {
"@type": "PostalAddress",
"postalCode" : "105-0011",
"addressRegion": "東京都",
"addressLocality": "港区",
"streetAddress": "芝公園4丁目1-2-3"
},
"telephone": "+81345678765",
"URL": "http://www.example.com/",
"employee" : ["山田太郎", "田中花子"]
}
</script>
employee プロパティは Person タイプを子どもにすることができるので、これを利用すると配列の中に JSON オブジェクトを記述することもできます。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "イグザンプル株式会社",
"address": {
"@type": "PostalAddress",
"postalCode" : "105-0011",
"addressRegion": "東京都",
"addressLocality": "港区",
"streetAddress": "芝公園4丁目1-2-3"
},
"telephone": "+81345678765",
"URL": "http://www.example.com/",
"employee" : [
{
"@type" : "Person",
"name" : "山田太郎",
"email" : "tyamada@example.com"
},
{
"@type" : "Person",
"name" : "田中花子",
"email" : "htanaka@example.com"
}
]
}
</script>
複数の構造化データ
JSON-LD フォーマット内で複数の構造化データを JSON オブジェクトとして併記する場合は、最初から配列にする必要があります。
<script type="application/ld+json">
[
{
"@context": "http://schema.org",
"@type": "Corporation",
...
},
{
"@context": "http://schema.org",
"@type": "Person",
...
},
{
"@context": "http://schema.org",
"@type": "BreadcrumbList",
"itemListElement":
[
...
]
}
]
</script>
構造化データテストツール
構造化データは、Google の提供している「構造化データテストツール」で確認することができるので、必ずエラーがないことを確認するようにします。
XML サイトマップ
サイトマップには、ユーザー用と検索エンジン用の2種類があります。
- HTML サイトマップ:サイトの利便性を向上させるために設置する HTML のページ
- XML サイトマップ:検索エンジンにサイト内のページを正確に通知するために設置する XML ファイル
HTML サイトマップは、ユーザーが簡単に目的のコンテンツを見つけやすいようにするページのことで、サイトのユーザービリティ向上を目的としています。(SEO 的にも有効)
XML サイトマップは、それを設置することで検索エンジンが、そのファイルを読み込みサイトの正確な情報を把握することができます。以下は Google Search Console ヘルプ(サイトマップについて)からの抜粋です。
サイトマップが必要かどうか
サイトの各ページが適切にリンクされていれば、Google のウェブクローラは通常、サイトのほとんどのページを検出できます。その場合でも、特にサイトが次のいずれかの条件に該当する場合に、サイトのクロールを改善する手段としてサイトマップが役立ちます。
- サイトのサイズが非常に大きい。
- サイトにどこからもリンクされていない、または適切にリンクされていないコンテンツ ページのアーカイブが大量にある。
- サイトが新しく、外部からのリンクが少ない。
- サイトでリッチメディア コンテンツを使用している、サイトが Google ニュースに表示されている、または他のサイトマップ対応アノテーションを使用している。
以下で扱うサイトマップは検索エンジン用の XML サイトマップ(sitemap.xml)のことです。
Search Console ヘルプの関連ページ:サイトマップの作成と送信
サイトマップ作成の注意点
サイトマップ作成においては、以下のような注意事項があります。
- 完全修飾 URL(絶対パス)を使用します
- ファイルは UTF-8 エンコードで作成し、適切に URL をエスケープする必要があります
- 大きいサイトマップは分割して小さいサイトマップにします(URL は 50,000 件以下、ファイルサイズは圧縮されていない状態で 50 MB 以下にする必要があります)
ツール を利用して sitemap.xml を作成
Web 上で XML サイトマップファイルを簡単に作成することができる無料のツールがあるので、それらを利用するのが一番簡単です。代表的なものには、以下のようなものがあります。
使い方は、XML サイトマップファイルを作成したい URL を入力して、作成するボタンを押すだけです(オプションの選択もありますが、ここでは省略します)。
- sitemap.xml Editor:ページ数の上限が1000(登録等の手続き不要)
- FC2サイトマップ:各検索エンジンへの登録状況を確認することも可能
- Xml-Sitemaps.com:英語のサイトですが、WordPress のサイトでも作成可能。ページ数の上限が500(無料の場合)。
- Google XML Sitemaps:WordPress 用のプラグイン
自分で sitemap.xml を作成
自分で sitemap.xml を作成することも可能です。その場合は、以下のような形式で記述します。
参考サイト:サイトマップの XML 形式(sitemaps.org)
サイトマップの記述ルールは次のとおりです。
- <urlset> タグで始め、</urlset> タグで閉じます。
- <urlset> タグ内にネームスペース (プロトコル標準) を指定します。
- <url>~</url>に個々の URL の情報をタグを使って記述します。
- 各親タグ <url> に子エントリ <loc> 等のタグを含めます。
1行目:文字コード(UTF-8エンコード)の宣言(必須)
2行目:XMLネームスペースの宣言(必須)。<urlset> タグはサイトマップ に関する情報を囲むためのタグです。
3行目:<url> タグ(必須)。個々の URL に関する情報を囲みます。このタグの間(<url>~</url>)に、<loc> などのタグを記述します。
4行目:<loc> タグ(必須)。ページの URL を指定します。
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<url>
<loc>https://www.webdesignleaves.com/pr/</loc>
<priority>1.0</priority>
<lastmod>2018-04-24T21:55:49+09:00</lastmod>
<changefreq>monthly</changefreq>
</url>
<url>
<loc>https://www.webdesignleaves.com/pr/index.html</loc>
<priority>0.8</priority>
<lastmod>2018-04-24T21:55:49+09:00</lastmod>
</url>
<url>
<loc>https://www.webdesignleaves.com/pr/html/index.html</loc>
<priority>0.8</priority>
<lastmod>2018-04-24T08:46:04+09:00</lastmod>
</url>
・・・中略・・・
</urlset>
必須ではありませんが、以下のタグを使って URL の更新日や更新頻度、優先順位を記述することができます。参考ページ:XML タグ定義(sitemaps.org)
<priority>
1.0がもっとも重要で、0.1が重要でないことを意味し、ホームページ内の他の URL と比較した場合の優先順位を指定します。ページのデフォルトの優先度は 0.5 です。検索結果に影響を与えることはなく、ホームページ内の相対的な優先順位を表します。
<lastmod>
URL の最終更新日を、「YYYY-MM-DDThh:mmTZD」の形式で指定します。
<changefreq>
ページの更新頻度(目安)を指定します。 クロールされる頻度に影響を与える可能性があります。値は次の7種類です。
- always
- hourly
- daily
- weekly
- monthly
- yearly
- never(アーカイブ ページ用)
サイトマップ インデックス ファイル
サイトマップが多数(複数)ある場合、サイトマップ インデックス ファイルを作成(使用)して一括送信することができます。
参考ページ:
複数のサイトマップの管理を簡略化する(Search Console ヘルプ)
サイトマップ インデックス ファイルを使用する場合(sitemaps.org)
複数のサイトマップ ファイルを送信できますが、以下のような制限があります。
- 各サイトマップ ファイルにリストする URL は 50,000 個まで
- ファイル サイズは 50 MB (52,428,800 バイト) 以下とする必要があります
また、必要な場合は、サイトマップ ファイルを gzip 形式で 50 MB 以下に圧縮して、サーバーの負荷を軽減できます。
複数のサイトマップを使用する場合は、サイトマップ インデックス ファイルに各サイトマップ ファイルをリストする必要があります。また、サイトマップと同様に、サイトマップ インデックス ファイルは UTF-8 エンコードで作成する必要があります。
サイトマップ インデックス ファイルでは、次の XML タグを使用します。
- sitemapindex - ファイルを囲む親タグ。<sitemapindex> タグで始め、</sitemapindex> タグで閉じます
- sitemap - ファイルにリストされた各サイトマップの親タグ(sitemapindex の子タグ)。
- loc - サイトマップの URL(sitemap の子タグ)。
- lastmod - サイトマップの最終更新日(省略可)。
以下は、2 つのサイトマップ(sitemap1.xmlとsitemap2.xml)を指定する XML 形式のサイトマップ インデックスの例です。
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>http://www.example.com/sitemap1.xml</loc>
<lastmod>2017-06-18T08:35:38+09:00</lastmod>
</sitemap>
<sitemap>
<loc>http://www.example.com/sitemap2.xml</loc>
<lastmod>2017-06-07</lastmod>
</sitemap>
</sitemapindex>
インデックス ファイルを作成して保存したら、すべてのサイトマップをホストサーバーの同じ場所にアップロードして保存した上で、インデックス ファイルだけを Google に送信(通知)します。
サイトマップ ファイルの場所
サイトマップ ファイルを配置する場所によって、サイトマップに含めることのできる URL は異なってきます。
サイトマップ ファイルを http://example.com/catalog/sitemap.xml に置いた場合は、http://example.com/catalog/ から始まる URL を含めることができますが、
http://example.com/images/ から始まる URL を含めることはできません。
サイトマップにリストされているすべての URL は、同じプロトコル (http または https 等) を使用し、サイトマップと同じホスト上に存在していいる必要があります。
サイトマップは、ウェブ サーバーのルート ディレクトリに置くことが推奨されています。 たとえば、ウェブサーバーが example.com にある場合、サイトマップ インデックス ファイルは http://example.com/sitemap.xml に置きます。
参考:サイトマップ ファイルの場所(sitemaps.org)
検索エンジン(Google)に通知
サイトマップを作成し、ウェブサーバーに配置したら、検索エンジンにその場所を伝える必要があります。
サイトマップを Google が使用できるようにするには、Search Console を使って通知するか、サイトマップを robots.txt ファイルに追加します。
Search Console を使って通知する場合
Search Console にログインしたら、該当するドメイン(プロパティ)をクリックし、左メニューにある「クロール」を展開し「サイトマップ」をクリックします。
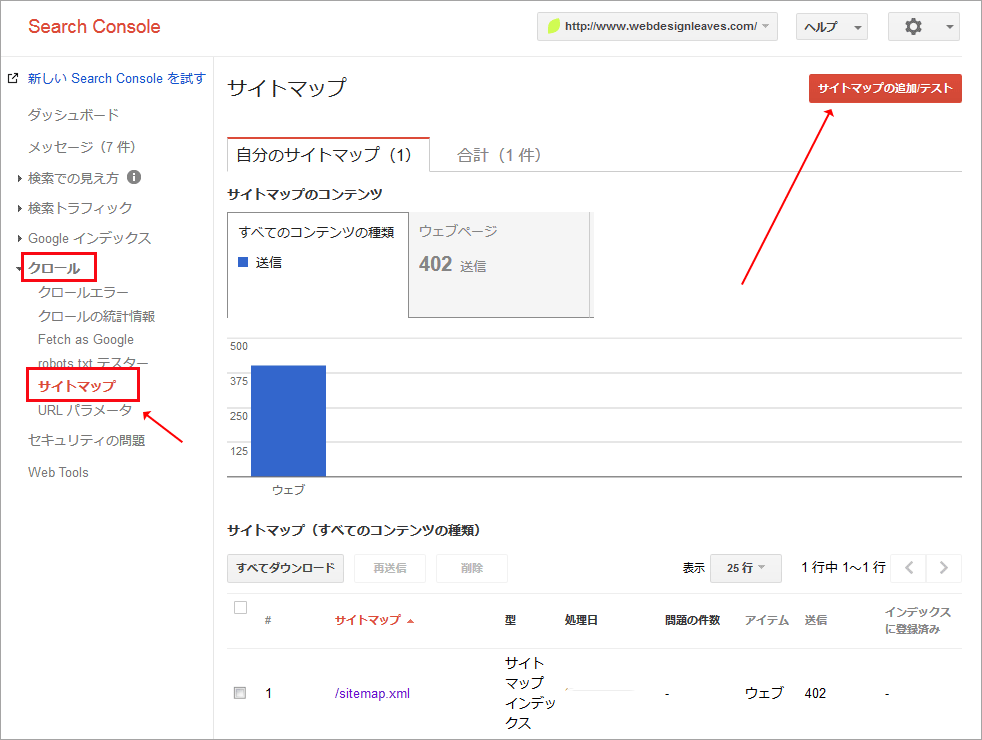
続いて右上の「サイトマップの追加/テスト」をクリックして、アップしたサイトマップの URL を入力し、「送信」をクリックして、Google に通知します。(サイトマップ インデックス ファイルを作成している場合は、その URL のみで大丈夫です)
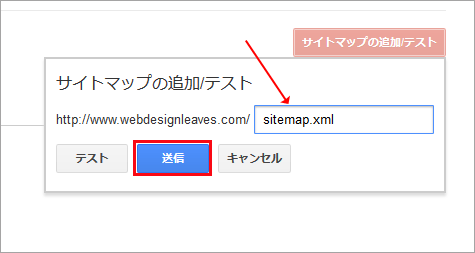
また、「テスト」をクリックすると、サイトマップに問題がないかを確認することができます。「テスト結果の表示」をクリックして確認します。
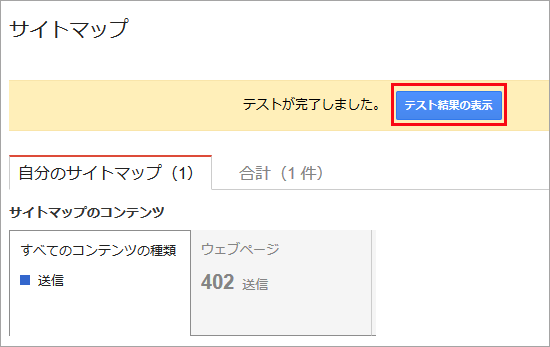
インデックスに登録済みになるには、ある程度の時間がかかります。今回は通知してから登録されるまでに24時間以上かかりました。インデックスに登録されると、以下のように赤いグラフで表示されます。
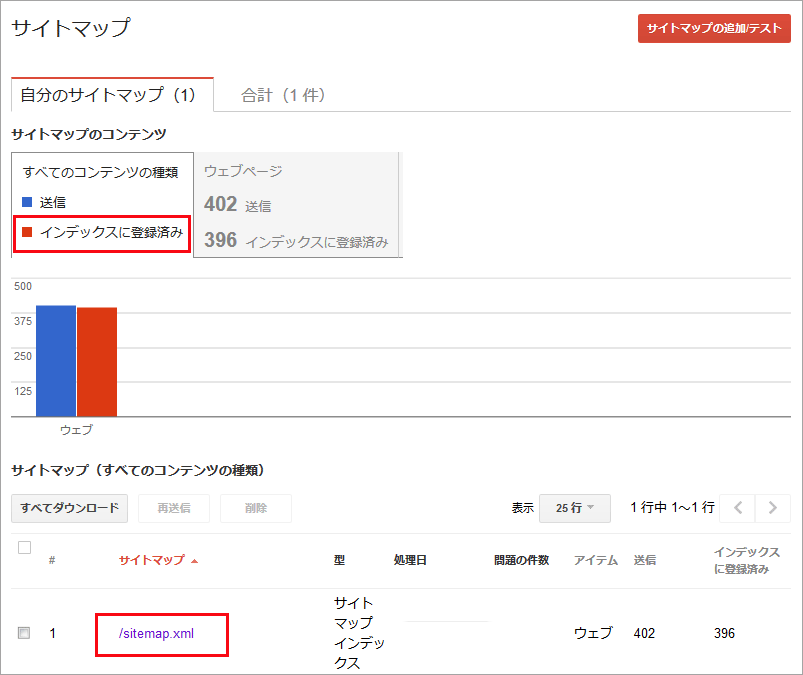
/sitemap.xml と表示されているリンクをクリックすると、その詳細(エラーがないか等)を確認することができます。
サイトマップがインデックスファイルの場合は、そのファイルに記載されているサイトマップが更に表示されて、それぞれを確認することができます。以下は sitemap.xml に2つのサイトマップ(sitemap_pr.xml と sitemap_wp.xml)を記述してある場合です。

サイトマップの場所を robots.txt ファイルで指定する場合
robots.txt ファイルを使用してサイトマップの場所を指定することもできます。その場合は次の行を追加します(URLやファイル名を適宜変更します)。
Sitemap: http://www.example.com/sitemap.xml
サイトマップ インデックス ファイルを使用する場合は、そのファイルの場所だけを含めることができます。 インデックス ファイルでリストされている個々のサイトマップをリストする必要はありません。
また、robots.txt ファイルごとに複数のサイトマップを指定できます。
Sitemap: http://www.example.com/sitemap-host1.xml Sitemap: http://www.example.com/sitemap-host2.xml
robots.txt
robots.txt とは、 検索エンジンのロボット(クローラー)の動きを制御するためのテキストファイルです。
検索エンジンのクローラーにサイトの一部や特定のページをクロールして欲しくない場合などに robots.txt を作成しますが、必須ではありません。(サイトのページをすべてクロールさせたい場合は、robots.txt ファイルを作成する必要はありません。)
robots.txt を使いクロールの最適化(検索エンジンに表示される必要のないページへのクロールを制御し、重要なページのみを検索エンジンに認識してもらい、クローラーの巡回頻度を上げること)により SEO 的に有利になる可能性があります。
以下は Search Console ヘルプの「robots.txt ファイルについて」からの抜粋です。
robots.txt ファイルはサイトのルートに配置するファイルで、検索エンジンのクローラにアクセスされたくないサイトのコンテンツを指定します。
robots.txt の使用目的
- 画像以外のファイル
- 画像以外のファイル(つまり、ウェブページ)の場合、Google のクローラによってサーバーに大きな負荷がかかったり、サイト上の重要でないページや類似するページのクロールにクロールの割り当てを費やしたりするのを避けることを主な目的として、トラフィックのクロールをコントロールするためだけに robots.txt を使用します。
Google 検索結果でウェブページを非表示にすることを目的に robots.txt を使用しないでください。 これは、他のページからそのページへのリンクがあると、robots.txt ファイルを経由しなくてもページがインデックス登録される可能性があるためです。検索結果からページをブロックする場合は、パスワードでの保護や noindex タグまたはディレクティブなど、別の方法を使用してください。
- 画像ファイル
- robots.txt は、画像ファイルが Google 検索結果に表示されないようにします(ただし、他のページやユーザーが画像にリンクするのを防ぐことはできません)。
ファイル形式と場所
- robots.txt は、ASCII または UTF-8 のテキストファイルです。他の文字は使用できません。
- ファイル名は robots.txt でなければなりません。
- 各サイトに含めることができる robots.txt ファイルは1つだけです。
- robots.txt ファイルは、適用するウェブサイトのルートに配置する必要があります。http://www.example.com/ の場合、http://www.example.com/robots.txt に配置する必要があります。サブディレクトリ(例: http://example.com/pages/robots.txt)には配置できません。
- robots.txt ファイルは、サブドメイン(例: http://website.example.com/robots.txt)や、標準以外のポート(例: http://example.com:8181/robots.txt)に適用することもできます。
robots.txt ファイルの書き方
以下は、robots.txt の例です。#から始まる行はコメントアウトです。「#」文字を使用して、ファイル内の任意の場所にコメントを含めることができます。
参考ページ:
Robots.txt の仕様
robots.txt ファイルを作成する
# Googlebot という名前のクローラ(ユーザーエージェント)に対する指示 User-agent: Googlebot Disallow: /nogooglebot/ # 他のすべてのクローラ(ユーザーエージェント)に対する指示 User-agent: * Allow: / # サイトマップの場所の指定 Sitemap: http://www.example.com/sitemap.xml
- 2~3行目:Googlebot クローラという名前のユーザーエージェントに、フォルダ http://example.com/nogooglebot/ やそのサブディレクトリをクロールしないようにする指示。
- 6~7行目:他の全てのユーザー エージェント(*)は、すべてサイト全体(/)にアクセスできることを明示(デフォルトでフルアクセス権限が付与されるため、このルールを省略しても結果は同じ)。
- 10行目:サイトマップが http://www.example.com/sitemap.xml にあることを伝える
robots.txt ファイルは、1 つまたは複数のルールセットで構成されます。
各ルールは、1 つまたは複数のユーザーエージェント(クローラ)を指定して、そのエージェントによるアクセスを許可する(または許可しない)ディレクトリやファイルを指定します。
※ ルールは上から下に順番に処理されます。また、ルールでは大文字と小文字が区別されます。
以下が基本的な書式です。
各ルールセットは User-agent 行で始まり、この行でルールの適用対象を指定し、Disallow: や Allow: でアクセスの制御をします。
User-agent: Disallow: Allow: Sitemap:
- User-agent:
-
必須。ルールごとに 1 つまたは複数
ルールの適用対象となる検索エンジン ロボットの名前を指定します。アスタリスク(*)を使用すると、各種 AdsBot クローラを除くすべてのクローラに適用されます。AdsBot クローラは明示的に指定する必要があります。
クローラ名のリスト:Google クローラ
- Disallow:
-
ユーザー エージェントによるクロールを許可しないディレクトリやページを指定します。
- Allow:
-
ユーザー エージェントによるクロールを許可するディレクトリやページを指定します。
※ Allow を使用すると、Disallow をオーバーライドして、許可されていないディレクトリ内のサブディレクトリやページのクロールを許可できます。
ルールごとに Disallow または Allow のいずれかが少なくとも 1 つ必要です。また、ページやディレクトリを指定する場合は、以下に注意します。
- ページの場合は、ブラウザで表示される完全なページ名にする必要があり、ルートドメインに対する相対 URLで指定します。
- ディレクトリの場合は、末尾を「/」にする必要があります。
- パスのプレフィックスやサフィックス、文字列全体に対してワイルドカード(*)を使用できます。
- Sitemap:
-
省略可能。複数可。ファイル単位で指定します。
対象ウェブサイトのサイトマップがある場所を指定します。また、複数のサイトマップを指定することもできます。
以下は2つのルールで構成されるファイルの例です。
User-agent: googlebot Disallow: /directory1/ Disallow: /directory2/ Allow: /directory2/subdirectory1/ User-agent: * Disallow: /
- 1~4行目:ディレクトリ /directory1/ と /directory2/ 及びその配下のディレクトリを googlebot からブロック。ただし、directory2/subdirectory1/ へのアクセスは許可
- 6~7行目:サイト全体をその他のクローラからブロック
以下は、WordPressの管理画面のディレクトリ以下を禁止(ブロック)する例です。
User-agent: * Disallow: /wp-admin/
パターンマッチ
「*」と「$」を使用して、不特定多数のファイルやディレクトリを指定することができます。
- 「*」はワイルドカードで、どんな文字にもマッチします。
- 「$」を最後に付けると URL(ファイルやディレクトリ名)の末尾とマッチします。
以下は特定のファイル形式のファイル(例: .gif)に対するクロールを禁止する例です。「*.gif$」は何らかの文字列で始まり「.gif」で終わる URL(ファイル名やディレクトリ名)を意味します。
User-agent: Googlebot Disallow: /*.gif$
「robots.txt ファイルを作成する」に実用的な robots.txt のルールが記載されています。
robots.txt テスターでテスト
robots.txt を作成したり、編集した場合は、Google が提供する確認ツール「robots.txt テスター」でチェックするのが確実です。
robots.txt テスター ツールでは、Google のユーザーエージェントやウェブクローラ(Googlebot など)に関してのみ robots.txt のテストを行います。他のウェブクローラが robots.txt ファイルをどのように解釈するかを予測することはできません。
参考ページ:robots.txt テスターで robots.txt をテストする
サイトのルートに robots.txt を設置(アップロード)して、「robots.txt テスター」のページにアクセスします。管理しているサイトが複数ある場合は対象のサイトを選択します。または、Search Console から「クロール」→「robots.txt テスター」でもアクセスできます。
初めての場合は、まだ Google がその robots.txt を認識していないため、以下のような「robots.txt が見つかりません(404)」というエラーが表示される場合があるようです。その場合は「閉じる」をクリックします。
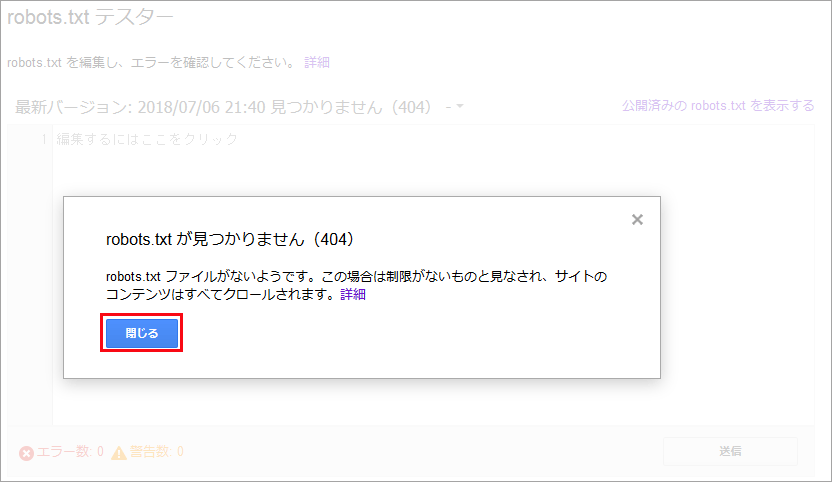
確認のため「公開済みの robots.txt を表示する」をクリックすると、ブラウザで robots.txt にアクセスするので、内容が表示されれば大丈夫だと思います。内容が表示されない場合は、.htaccess などでテキストファイルがブロックされていないか等を確認します。続いて「送信」をクリックします。
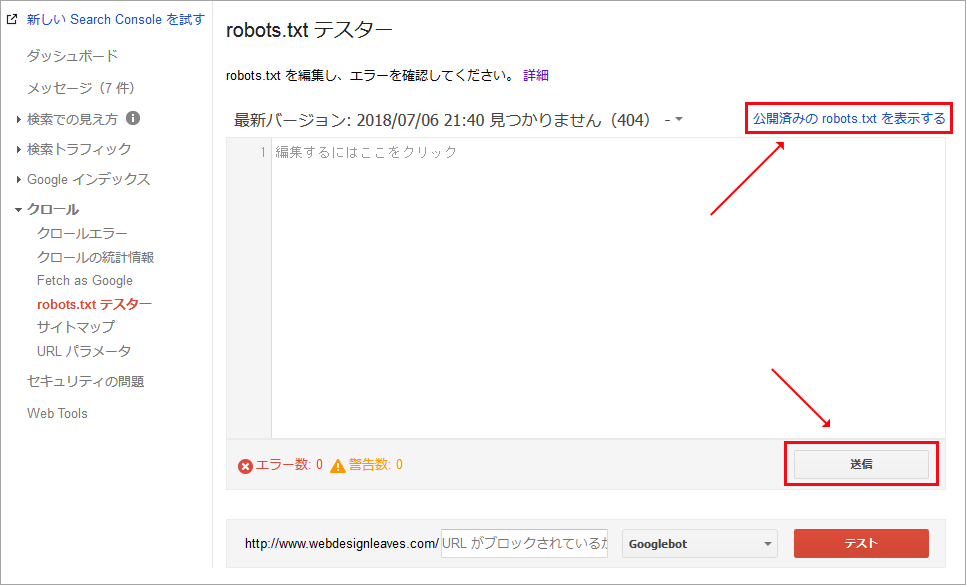
以下が表示されるので「送信」をクリックします。
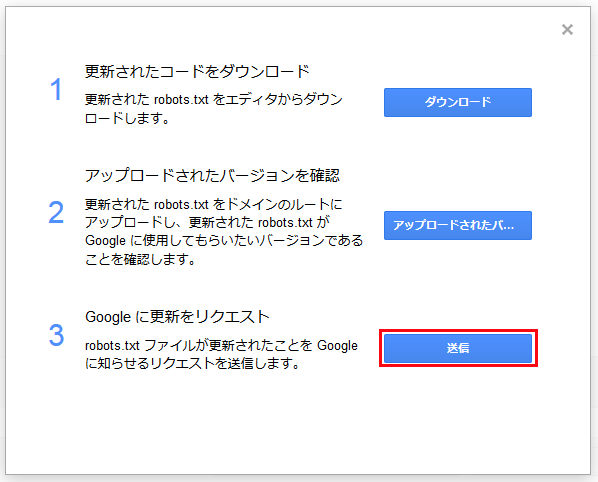
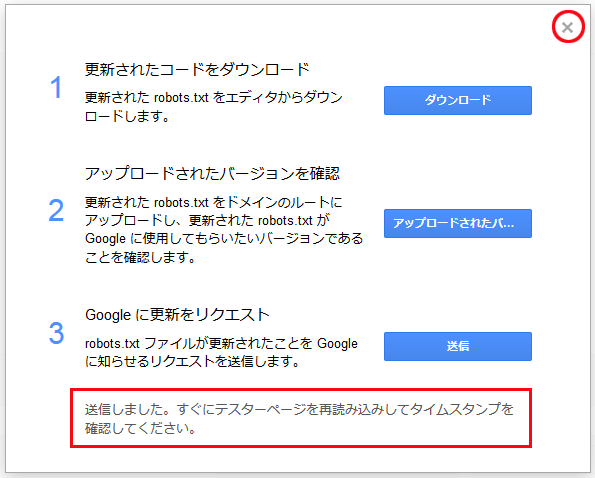
「送信しました。すぐにテスターページを再読み込みしてタイムスタンプを確認してください。」と表示されるので、右上の「X」をクリックして閉じます。
以下のようなページが表示されるので、エラーや警告を確認することができます。エラーや警告の数が0であれば問題ありません。エラーがあれば記述などを確認して修正します。
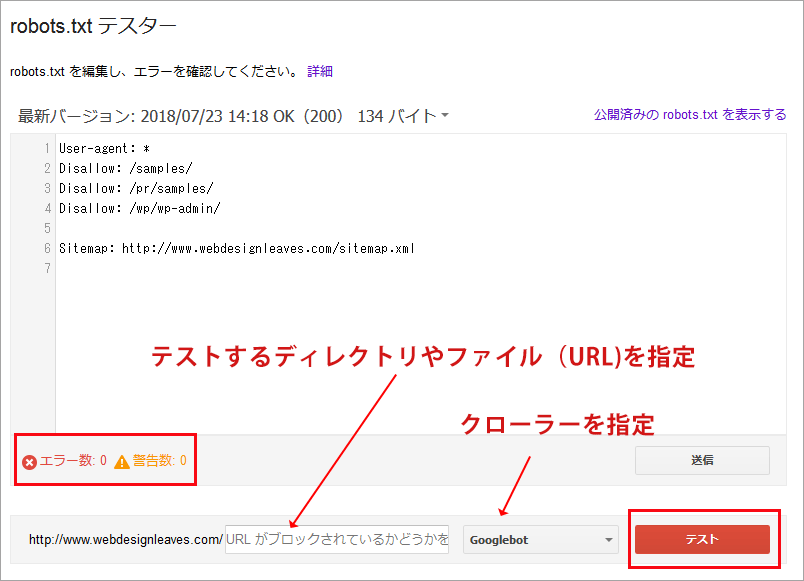
続いて、robots.txt に書かれていることが実際に機能しているかを確認します。
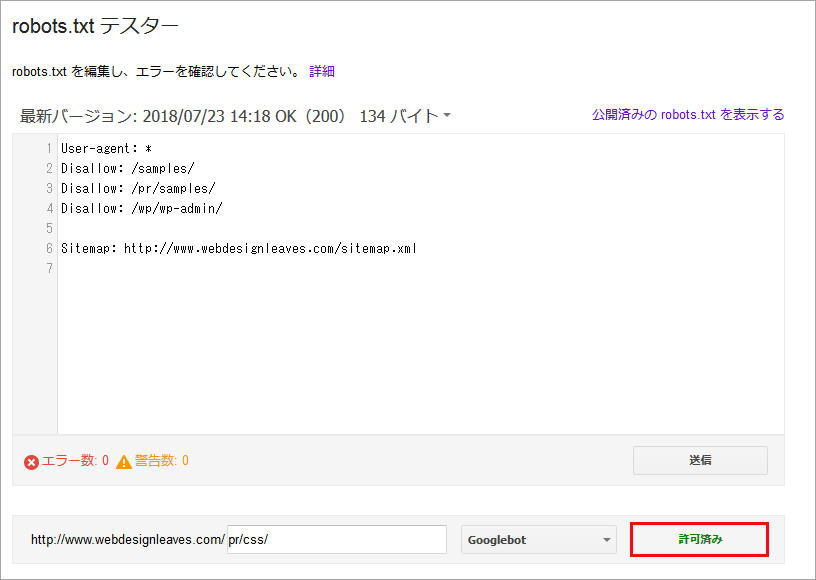
フォームに URL を入力し、「テスト」をクリックします。必要に応じてクローラーを指定することもできます。また、robots.txt の内容が反映するのに時間がかかる場合があります。その場合、少し時間をおいて確認してみます。
以下はブロックするディレクトリを入力して、「ブロック済み」になっていることを確認した例です。ブロックを指定した記述が赤色でハイライトされます。
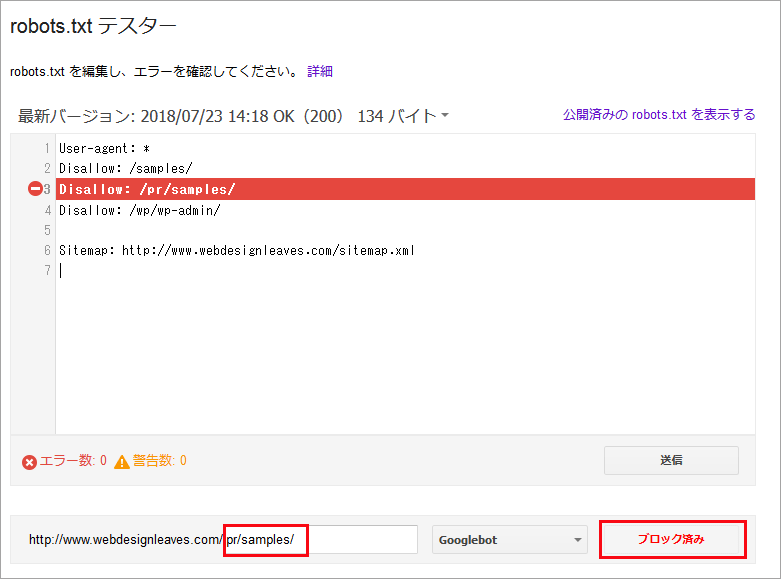
以下はブロックされるべきでないディレクトリを確認した例です。その場合、「許可済み」と表示されます。
注意点としては、robots.txt テスターのツールエディタでの変更内容はウェブサーバーに自動的に保存されるわけではないため、エディタから内容をコピーして、サーバーに保存されている robots.txt ファイルに貼り付ける必要があります。
AMP(Accelerated Mobile Pages)概要
※[追記] Google 検索などにおける「AMP の優遇」は2021年6月に終了しました。
AMP(Accelerated Mobile Pages)は Google と Twitter が共同で開発しているモバイルページでの表示を高速化するためのプロジェクト及びそのフレームワーク(や規格)のことです。
AMP を実装すると、モバイルページの表示速度が高速化してモバイルユーザーの満足度を上げることができます。
- AMP プロジェクトの公式ページ(日本語)
- Google 検索での AMP に関するガイドライン
- 顧客のサイトを AMP 化するための 8 つのヒント(Google ウェブマスター向け公式ブログ )
- Accelerated Mobile Pages プロジェクトについて(Google ウェブマスター向け公式ブログ)
- サイト運営者向け AMP 導入ガイド(PDF)
AMPでは、スマホ(モバイル)によるページ表示を高速化するために複数の技術を利用していてます。そのため以下のような規格を使ってページを作成する必要があります。
- AMP HTML(カスタム AMP プロパティで拡張された HTML5 )
- AMP JS(AMP HTML ページの高速なレンダリングを確実に行えるようにするもの)
- AMP Cache(キャッシュされた AMP HTML ページの配信)
具体的には、「通常のぺージ」と「AMP 用のぺージ」の2つのページを用意して、お互いのぺージに指定された方法で相互にリンクを貼ります。(AMP 用のぺージのみでも OK)
AMP 用のぺージの基本的な HTML は以下のようなものになります。AMP ではいくつかの HTML タグの使用に制限があります(使えないタグがあり、代わりに AMP 独自のタグを使う必要があります)。
<!doctype html>
<html amp lang="en"><!--AMP HTMLの宣言文-->
<head>
<meta charset="utf-8"><!--UTF-8 以外は許容されない-->
<title>Hello, AMPs</title>
<link rel="canonical" href="hello-amp.html"><!--PCページの指定-->
<meta name="viewport" content="width=device-width,minimum-scale=1,initial-scale=1">
<script type="application/ld+json">
//構造化データ マークアップ(JSON-LD)
{
"@context": "http://schema.org",
"@type": "NewsArticle",
"headline": "Open-source framework for publishing content",
"datePublished": "2015-10-07T12:02:41Z",
"image": [
"logo.jpg"
]
}
</script>
<style amp-boilerplate>body{-webkit-animation:-amp-start 8s steps(1,end) 0s 1 normal both;-moz-animation:-amp-start 8s steps(1,end) 0s 1 normal both;-ms-animation:-amp-start 8s steps(1,end) 0s 1 normal both;animation:-amp-start 8s steps(1,end) 0s 1 normal both}@-webkit-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@-moz-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@-ms-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@-o-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}</style><noscript><style amp-boilerplate>body{-webkit-animation:none;-moz-animation:none;-ms-animation:none;animation:none}</style></noscript>
<script async src="https://cdn.ampproject.org/v0.js"></script>
</head>
<body>
<h1>Hello Amp!</h1>
</body>
</html>
HTML の記述方法などは、以下の公式ページのドキュメントに記載されています。
関連ページ:AMP の導入と実装(基本的なこと)